
How do you control an epidemic? In that context, let me discuss the SIR model of disease and demonstrate it in action. It’s the one that gives rise to those curves we’ve seen so many of, the ones that we’re trying to flatten.

We classify people into three categories: 1) susceptible (S) haven’t got the disease yet, so they’re vulnerable to it; 2) infected (I) have got it, so they might even give it to others; 3) recovered (R) either got over it or died, and presumably won’t get it again. The mathematical variables are S = fraction of the population which is susceptible, I = fraction infected, and R = fraction recovered, hence the name “SIR model.”
They change in two ways. First, new people get infected. This depends on S, how many potential victims are available to infect, on I, how many are available to infect them, and a constant factor that I’ll denote by the letter a. If you’re infected, it’s how many people you infect per day (on average) until you recover, if everyone is available to be infected. Second, infected people either recover or die, which depends on I, how many are infected, and a constant factor I’ll denote by the letter b.
Those constants, a and b, are the control knobs on the spread of a disease. Sometimes folks use other (but equivalent) variables, but the model is the same and its results unchanged. Particularly interesting is their ratio 

If I set the constants to values a=0.5, b=0.1, begin with only 1 infected person per million population, and let the model run for a 120 days, then I get the graph (of infected fraction I) shown above.
At first, progress of the desease is exponential, dominated by new cases, with the difference 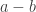
We can make this more plain by graphing the same thing, but on a logarithmic plot:

The first phase, exponential growth, shows as straight-line growth in the logarithmic plot, while phase two, exponential decline, shows as straight-line decline.
In the first graph we see that at one time, about 50% of the population is infected. Eventually nearly everyone (over 99.5%) gets the disease, so if 1% of infected die, that’s about 3.4 million dead Americans. The whole thing is over in a few months, but with half the population sick at one time, it will overwhelm the health care system.
In order to change course, we must change the growth constant a or the recovery constant b or both. There’s not much we can do about the recovery constant, but we can start in on the growth constant by noticing that it has (at least) two important factors. We can say that 
1: Reduce the probability of infection for each contact. Wear a mask, keep your distance (2m or 6ft).
2: Reduce the number of contacts. Close non-essential businesses, prohibit large gatherings.
When we do that, we decrease the spread rate a. It’s a fact. If we stop doing it, the spread rate a will increase. That too is a fact.
Let’s run the model again, but this time we’ll change the control settings in mid-stream. After 25 days, we’ll lower the spread rate a, dramatically in fact. Then we let things continue. What’s notable is that the new value of a is less than b, so the disease can’t grow, it starts to die out.

We won’t see that right away. That’s because we don’t really know the number I of infected. We often see graphs of “total cases,” but that’s the infected plus the recovered. What we see more often is new cases per day.
And we don’t even see that; we see new detected cases per day. Cases don’t get detected right away; for most people they are never detected at all, and those we do find are often those very sick, long after they contract the disease. I computed the number of new cases per day, then applied a Gaussian smooth to simulate spreading the detections out over a considerable time span. Here’s the result:

This is what it looks like if you get hit hard by the disease at the outset, then put strong measures in place to reduce the epidemic. They work. Like they did in New York state:

That’s how you control an epidemic.
Let’s do another simulation. At the start, we’re hit hard but not as hard. Then we institute control procedures, but not as tight as they did in New York. As a result, we keep the new-case level under control, but we barely get it to decline.
After a couple of months of that, we loosen controls. We have to save the economy! Let’s go to the beach! Disney World!! I need a haircut!!! It’s not as loose as it was when we did nothing — but it’s no longer tight enough to keep the lid on. Here’s the result, compared to what happened in the state of Florida:

That’s how you lose control of an epidemic.
This blog is made possible by readers like you; join others by donating at My Wee Dragon.



Excellent post as always, Tamino. I shared it. One quibble: In your list of ways to reduce spread, #1, distance keeping should be first and bold. “Masks” for the general populace means face coverings of all sorts, and even if they are surgical masks or N95 masks then usually they are improperly fitted and maintained such masks. Aerosols are not much prevented from exiting or entering by the general public’s “masks.” Even properly fitted surgical masks are not much good at filtering aerosols, which is why N95 masks even exist.
Yes, the main mechanism for this particular virus’s spread is droplets rather than aerosols, and “masks” of all sorts do a decent job of stopping droplets. But droplets also tend to drop to the ground within about three feet of someone who is not talking loudly, coughing, sneezing, singing, or yelling. Which is why six feet is a good recommendation of a minimum distance from such people. And yes, some aerosol production very close to the mouth and nose is stopped by arresting droplets before that happens, so masks stop creation of some aerosols.
Nonetheless, the primary prevention should be to stay really far away from everybody, indoors or outdoors. For example, if you are always at least 200 feet away from everybody and you are outside, your wearing of a mask will not add protection.
“Masks” are valuable when adequate distancing cannot be maintained, when you are sharing slowly circulated air with other people, or if anybody is coughing, sneezing, singing, laughing, yelling, or talking loudly for any reason, or if you or anybody around you is suspected of being infected. Yes, such a large number of situations means that wearing a mask almost always when you are around other people almost certainly is beneficial enough to overwhelm the trivial cost and inconvenience of wearing it.
The risk of overemphasizing “masks” is that the public thinks that as long as they are wearing a mask they need not do any of the other things. I see that behavior every day. If I must choose between being close to someone wearing a mask, or far away from someone not wearing a mask, I choose the distant person.
Great job Tamino! Any chance of rerunning the Red State Blue state graph?
People emit a continuum of droplet sizes, from below 1 μ to way above 100 μ. (The difference between “droplets” and “aerosols” is somewhat arbitrary. It’s just droplets of different size.) Because of volume reasons, the bigger droplets contain the vast majority of viruses. This I got from literature and some logical thinking. And it’s those bigger droplets, which are held back with at least some efficiency also by improvised masks, provided the airstream does pass through the tissue. That’s probably, why it can be said, that a mask protects the other people from you, but not so much vice versa.
If they are emitted, in normal humid air the water from the bigger droplets evaporates within a time span between a fraction of a second to a couple of seconds (depending on the size), reducing its mass to a couple of percent, leaving some organic matter from the mucus. (Information from literature.) Most of the droplets become so lightweight, that they are carried away even by the thermal upstream plume enveloping as all. Only few do actually make it to the floor. Thus, they are dispersed in a room according to the internal air flow. The half-life in air has been reported to be around 3 hours. So in a closed room with infectious persons in it, we get a constant virus concentration after a couple of hours. This is why closed rooms are a problem of their own. For obvious reasons, the probability of infections raises quadratically with the number of persons in the room and about linearly with time, at least in the beginning.
With normal talking, droplets are not to be expected to be shot around, but stay rather confined because of their high air resistance / mass ratio. Sneezing and coughing is another matter, though.
In open air, there is no steady state virus concetration to talk of. If distance is kept, one has only to be aware of the wind, which may carry your virus plume directly to your partner. So here the wind should blow across your connecting line.
Talking loudly or singing are especially virus shedding activities.
“If distance is kept, one has only to be aware of the wind, which may carry your virus plume directly to your partner. So here the wind should blow across your connecting line.”
You should come and explain this to people here in the windy Pass. They should not stand upwind and shout to be heard over the wind noise.
Sounds like you’ve got it now, so why don’t you explain it to them?
Michael Osterholm is a distinguished epidemiologist. . He was asked to contribute to the National Academies Standing Committee on Emerging Infectious Diseases and 21st Century Health Threats “Rapid Expert Consultation on the Effectiveness of Fabric Masks for the COVID-19 Pandemic (April 8, 2020)”.
This study is located at this link: https://www.nap.edu/read/25776/chapter/1
Osterholm wears a mask when he is out in public. However, he says this about the fact that the CDC started recommending that the general public wear makeshift homemade masks:
“I believe this cloth mask recommendation situation represented the other low point in CDC’s response to COVID-19, with the other being the failed testing situation”.
Osterholm has a podcast. He discusses masks in a special episode located here: https://www.cidrap.umn.edu/covid-19/podcasts-webinars/special-ep-masks
Darn right. Posted to LinkedIn.
Also “The Coronavirus surge that Texas could have seen coming“: The New Yorker.
Lessee… South Carolina, South Carolina… Aha!
https://rt.live/us/SC
Hmmm. Where have I seen that shape before?
It is really easy to lose control over COVID-19. Here in Slovenia, we had less than 7 new cases per week, and government started to lift the restrictions (reasonably at the time). However, since Slovenia is small country, and people started to travel to countries which didn’t have disease under control – and the result is, that we are back to 14 cases daily and the exponential form is taking the shape, as people still think that epidemic is over and do not keep social distancing (at least not enough – people are more careful than before first epidemic, but not good enough and some measure a still in order, such as ban on events with more than 500 people, and also school year has ended so schools are almost closed now).
Thank you David Lewis for the link to the Osterholm interview. It is excellent, and there is a transcript for folks who don’t want to listen.
Wow! A truly excellent review of COVID-19 infection protection from three protective measures: physical distance, masks (N95, surgical, and 12-13 layer cotton), and eye protection. Methodology is spectacular; they even used Bayesian methods. Study commissioned by the WHO; this study is an excellent example of the enormous value of that organization.
1 meter or more distance is key; see Figure 3. 2 meters is better. 3 meters still better. Masks help too, but mostly when distances are less than the above. Did not include face coverings of lesser quality than 12-13 layer cotton, so I infer that with those, distance is even more important than with surgical or N95.
Published in The Lancet yesterday.
https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(20)31142-9/fulltext