
Euler appeared, advanced toward Diderot, and in a tone of perfect conviction announced, “Sir,, hence God exists—reply!”.
One is tempted to be amazed how often such arguments are made about serious issues. But it shouldn’t be such a surprise when one considers how often people are taken in by such sophistry. If you can’t persuade them with logic, dazzle them with bullshit.
A recent comment by “VS” at Bart Verheggen’s blog suggests:
In other words, global temperature contains a stochastic rather than deterministic trend, and is statistically speaking, a random walk. Simply calculating OLS trends and claiming that there is a ‘clear increase’ is non-sense (non-science). According to what we observe therefore, temperatures might either increase or decrease in the following year (so no ‘trend’).
The original “random walk” was posited by Karl Pearson in a letter to Nature in 1905. In Pearson’s version, a man starts at the origin and walks a fixed distance in any direction. He then walks the same distance again, in some randomly chosen direction. This process repeats. Pearson was interested in the probability that after n such steps, the man had travelled distance r from his starting point. Pearson’s question was answered a week later by Lord Rayleigh, who had already worked out the solution as it was related to some problems in physics (relevant to diffusion). Rayleigh also worked out the random walk in which the length of each step was not constant.
Ironically, it was also in 1905 that Einstein published his work on the Brownian motion — the small jittery motion of microscopic particles (like dust or pollen grains) suspended in a fluid. Einstein posited that the jitters were caused by the collision of individual molecules of the fluid with the microscopic particles, and used observations of the Brownian motion to deduce the probable size of the molecules in the fluid, one of the first realistic estimates of the size of individual molecules.
The essence of a random walk is that it is the cumulative sum of random terms. We can generate a 1-dimensional random walk by generating random numbers (we could use, for example, Gaussian white noise) and summing them up. This would give us a series, which we can posit as a time series
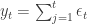
where 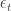
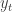

We can write our random walk as

We can also write this as
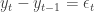
We can even define the lag operator L as the operator which transforms a time series to its 1-time-previous values
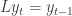
to write the time series as
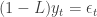
It’s also common to define the difference operator 
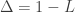
so that
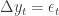
Random walks are not just simple random series, and they’re not “stationary” time series. Because of this, they can give a false impression of the presence of a time trend. If, for instance, I fit a trend line to the first random walk I generated, I get this:

and the test statistic (t=13.2) indicates that it is definitely statistically significant. But this is a case where we need to be aware of what the test statistic means. The null hypothesis is that the data are white noise. The significant test statistic means we can reject that null hypothesis. That only means that the data are not white noise — which is correct. It does not mean that the data exhibit a linear trend over time.
Our form for defining the random walk is similar to the form of an ARMA (autoregressive moving-average) process. An ARMA(p,q) process (autoregressive moving-average of order p,q) is
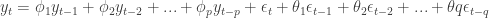
or, using the lag operator,
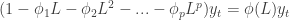
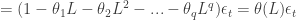
where 
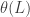
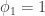

We can then study the roots of the characteristic polynomial. If one of the roots is equal to 1 (a “unit root”), then we can factor the AR operator into the form
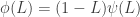
Then our process is

The “1-L” operator (the difference operator) can be thought of as an “integration” operator, so such a process is called an integrated autoregressive moving-average (or ARIMA) process. We can sometimes factor multiple instances of the difference operator out of the AR process, giving an ARIMA(p,d,q) process: AR of order p, integrated d times, MA of order q.
If the AR operator has a unit root (so that we can factor out a difference operator), we tend to classify it as ARIMA rather than ARMA. We also know that the time series is not stationary — it doesn’t show behavior which is essentially the same at different times. A random walk, for instance, shows ever-growing variance, so that as time continues indefinitely into the future it can wander off without bound. A random walk is unbounded.
Yet we know that global temperature is bounded. Therefore it’s not a random walk. “VS” replied to this saying
Temperature may be ‘bounded’ over it’s long 100,000 year cycle (as observed over the past 500,000 or so years), however, on the subset of a 150 years or so, on which we are formally studying it, it can be easily classified as a random walk.
It’s interesting that a simple, one-sentence fact (temperature is bounded) already forces “VS” to move the goalposts.
How can we tell the difference between a genuine trend, and an apparent one due to some process that has a unit root? One approach is to apply a unit root test. The most straightforward is the Dickey-Fuller, or DF test. It’s based on the idea that a stationary process tends to return to its mean value, while a unit-root process has no such tendency, it wanders in a random way regardless of its present value. This means that the value of a given increment (change from one time series value to the next) 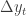

Therefore the Dickey-Fuller test performs a regression of increments
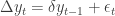
and tests whether the regression is significant. Note that although 
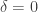
We must also be careful because the null hypothesis is not that the time series is white noise, so we can’t apply the usual t-test to the regression. Instead we compute a t value, but compare it to the Dickey-Fuller t distribution.
That’s fine as far as it goes, but if the process has a genuine trend but no unit root, then it won’t tend to return to a “mean value,” it will tend to return to the value of the trend line. So there are two further versions of the Dickey-Fuller test. One tests for the presence of a unit root in the presence of drift, using the regression
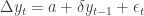
and the other tests for the presence of a unit root when there’s a deterministic trend,
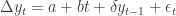
In all cases the null hypothesis is that a unit root is present. The Dickey-Fuller test is known to have low statistical power when the time series lacks a unit root but does show strong autocorrelation, so it may well fail to reject the null hypothesis even when it’s false.
Of course, the series of increments
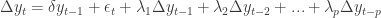
up to some order p. There are also, just as with the DF test, versions to allow for drift and trend
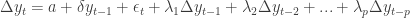
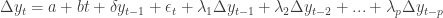
Another choice is the Phillips-Perron, or PP test. This uses a nonparametric alternative to regressing on lagged increments, and allows for different behaviors of the underlying random process (like changes in its variance).
It’s crucial to note that in the presence of a real trend, we have to use the versions of the ADF test which allow for it. Suppose, for instance, we generate some artificial data which are a linear trend plus white noise. I generated 130 such values here:

There’s nothing complicated about this time series, it’s a linear trend plus white noise. Let’s apply the ADF test using the R package “CADFtest.” It implements the covariate-adjusted ADF test, which allows us to test a time series along with some covariates, but if we don’t supply covariates it just computes the straight ADF test. It defaults to allowing for a trend, but if we disallow that using the command
CADFtest(y,type=”none”)
we get
ADF test
data: x
ADF(1) = 1.4382, p-value = 0.9623
alternative hypothesis: true delta is less than 0
sample estimates:
delta
0.01416970
Note that it has failed to reject the null hypothesis (p-value=0.9623, so we can’t even reject at 5% confidence let alone 95% confidence), therefore it indicates the possibility of a unit root. But we know that’s not the case! We can also apply the ADF test allowing for drift but not trend
CADFtest(y,type=”drift”)
which gives
ADF test
data: x
ADF(1) = -0.7466, p-value = 0.83
alternative hypothesis: true delta is less than 0
sample estimates:
delta
-0.01466259
Again we have failed to reject the null hypothesis, indicating the possibility of a unit root. But we still know that’s not so! The failure is because we have specifically excluded the possibility of an actual trend. When we allow for that
CADFtest(y) -or- CADFtest(y,type=”trend”)
we get
ADF test
data: x
ADF(1) = -8.8218, p-value = 1.968e-11
alternative hypothesis: true delta is less than 0
sample estimates:
delta
-1.184363
Now the null hypothesis is rejected at a significance level of 2 x 10^-11 (99.999999998% confidence). There’s no unit root (which we already knew).
If we apply the ADF test to the random walk to which we fit a (falsely significant) trend, we get
ADF test
data: y
ADF(1) = -2.6338, p-value = 0.2666
alternative hypothesis: true delta is less than 0
sample estimates:
delta
-0.151474
We fail to reject the unit-root hypothesis, as we should, since this is a random walk. If we restrict the ADF test to exclude a trend, or to exclude drift and trend, we get the same result. We can further test for a unit root with the PP test, which gives
Phillips-Perron Unit Root Test
data: y
Dickey-Fuller = -2.8724, Truncation lag parameter = 3, p-value = 0.2152
Again we can’t reject the unit root, and again that’s because there is one.
If you’ve read this far, you must be wondering what we get when we apply the ADF or PP unit-root tests to actual temperature data. Let’s take GISS data, annual averages from 1880 to 2009. First let’s look at the results supplied by “VS”:
** GISSTEMP, global mean, 1881-2008:
Level series, ADF test statistic (p-value<):
-0.168613 (0.6234)
First difference series, ADF test statistic (p-value<):
-11.53925 (0.0000)Conclusion: I(1)
** GISSTEMP, global mean, combined, 1881-2008:
Level series, ADF test statistic (p-value<):
-0.301710 (0.5752)
First difference series, ADF test statistic (p-value):
-10.84587 (0.0000)Conclusion: I(1)
I’m not sure why he’s using two GISSTEMP series, or what he means by “combined,” or why he uses 1881-2008 (since GISS extends from 1880 to 2009). But I ran the ADF test on GISS data (1880-2009) and got this:
ADF test
data: x1
ADF(1) = -4.2506, p-value = 0.005066
alternative hypothesis: true delta is less than 0
sample estimates:
delta
-0.3308484
The null hypothesis, of a unit root, is resoundingly rejected. We can also do the PP test, giving
Phillips-Perron Unit Root Test
data: x1
Dickey-Fuller = -5.1747, Truncation lag parameter = 4, p-value = 0.01
Again, the unit root is rejected.
The ADF test as implemented in the R package CADFtest also enables the user to allow for an excessively large number of lagged increment values. This is not recommended, but I did so anyway, with model selection by BIC (Bayesian Information Criterion). It doesn’t change the result. The unit root is rejected.
How did VS fail to reject it? I suspect he excluded a trend from his ADF test. He may also have played around with the number of lags allowed, until he got a result he liked. He excluded reality, and if you do that, you can “prove” whatever you want.
One final note: there’s an ever-growing number of “throw some complicated-looking math at the wall and see what sticks” attempts to refute global warming. It seems to me that a disproportionate fraction of them come from economists. Perhaps that’s because they fear the loss of corporate profit more than they fear danger to the health and welfare of humanity. Or perhaps it’s just a reflection of the rather poor track record of economists in general. When it comes to predicting the future, it’s well to compare the truly astounding successes of, say, physics, to, say, economics.



Economics: My favorite ‘science’.
Hey, at least its not psychology :P
pfft.. economics is just applied psychology.
Let’s see, you were finishing a manuscript on your analysis of GHCN data, writing a lengthy and fascinating post about the statistical properties of random walks, and presumably still sleeping, eating, and working at your day job.
I’m amazed. Thank you for taking the time to illuminate these topics.
+1.
I think it’s worthwhile to take a step back and recall that the global temperature is a dependent variable subject to the laws of physics. Kind of like the “Brownian motion” case considered by Einstein, there is a physical reason that the temperature may be drifting up, down, or around the place – something is bumping it along. To the extent that the temperature record CAN be considered as a random process, you’ve got to be able to link your proposed statistical process back to some physical reality.
If you’re going to take a ‘random walk’ seriously, you’ve got to be able to explain how the earth’s climate system can integrate significant quantities of heat over years and decades with only “random” variations in forcing (presumably solar/cosmic?). My understanding is that the atmosphere is a very “leaky” integrator (although the ocean can store much more heat over longer time spans) so the physical case for a pure “random walk” doesn’t seem to be very convincing. In reality, you’re going to need the forcing to be biased on the positive side, and if anything getting larger over time, in order to end up with positive trends over several decades. You might as well stick with the simpler theory that there IS a gradually increasing positive forcing going on…
An economist is a physicist taking a random walk (down Wall Street, with a bottle of Jack)
Physicists try to simplify things as much as possible, economists try to complicate them as much as possible and engineers try to split the difference.
Crank: 6 sentences, ~100 words of made-up junk (pulled from a much larger pile, I realize).
Tamino refuting crank: ~2000 words of arguments using mathematics, statistics, and physics — not to mention the ~20 equations, 3 plots, ~10 sets of computations — to refute said junk.
And that’s just to address a *single* piece of junk (see “Gish Gallop”). It’s always the same — the onus should be on the crank, not the science (or scientist), but it never is because such a concept never occurs to them.
Spaceman Spiff, while I agree with your larger point, one can summarise Tamino in the following elevator pitch (one sentence, thirteen words):
OK, guys, not to get in the way of the fun of bashing the dismal science, but as a physicist, I must point out that physics has its share of knob polishers, too:
Scafetta & West, G&T, our buddy Lubos, Happer,… Need I continue?
When you become an expert, it’s essential to know where your expertise ends our you wind up saying things that are REALLY, REALLY stupid.
That said, VS seemed to be a gristlegripper of the first order!
That’s because most economists firmly believe in the religion of unending exponential economic growth, utterly disregarding the biophysical and thermodynamic laws of objective reality. Infinite growth isn’t possible in a finite system. Or to quote Kenneth Boulding: “”Anyone who believes exponential growth can go on forever in a finite world is either a madman or an economist.”
Sadly, this neoclassical concept of infinite economic growth is what drives our society and culture. It has become as natural as breathing to practically everybody, ie something you never think about.
But in my view it is the root problem of which AGW is but a symptom. As long as this concept isn’t questioned, there is no possible way a solution will come about.
An economist is a physicist taking a random walk (down Wall Street, with a bottle of Jack)
Physicists try to simplify things as much as possible, economists try to complicate them as much as possible and engineers try to split the difference.
Bravo!
The next citation to ‘Only in it for the Gold’?
But … they’re outliers …
First: I second J – wow.
Second – I myself have used random walks to emphatically demonstrate that massive inequality is perfectly natural and to be expected. That’s science, that is:
http://www.coveredinbees.org/node/234
(p.s. in case the sarcasm doesn’t come across in the comment, please use a mental )
Thanks a lot, Tamino, for your detailed reply on the random walk issue.
From a physical perspective it’s also clear that the increase on global avg temp hasn’t been random: A random increase would cause a negative energy imbalance or the extra energy would have to come from another segment of the climate system (eg the ocean, cryosphere, etc). Neither is the case: There is actually a positive energy imbalance and the other reservoirs are actually also accumulating energy. Moreover, there is a known positive radiative forcing.
(I collected my thoughts on this random walk idea in a newer post: http://ourchangingclimate.wordpress.com/2010/03/08/is-the-increase-in-global-average-temperature-just-a-random-walk/)
A different question would be, if these data, without any physical constraints on it, could mathematically be described as ‘VS’ does (purely stochastic; random walk). In light of the physical system that these data are a part of, this is a purely academic mathematics question. The physics of it all sais that it hasn’t in fact been random, since that would inconsistent with other observations.
You provide solid reasoning here that even just mathematically, the increase in global avg temp can’t be classified as a random walk, and you provide a hypothesis as to why VS came to a different result: E.g. omitting the existence of a trend in his hypothesis testing, or cherrypicking a specific value for the lag. I’ll ask him.
I do have a question: Since there is some autocorrelation in the errors (or variations around the trend) in global avg temp data, the ordinary least squares regression will underestimate the error of the trend estimate (as you’ve stated in the previous thread). So how should one then calculate a trend, and the error in the trend? I assume that the best estimate of the trend is not affected much, merely the error. Eg I found a OLS trend of 0.17 (+/- 0.03) deg/decade from 1975 to 2009 (for HadCRU, NCDC and NOAA). Can I safely assume the ‘real’ trend to be centred around 0.17 indeed, but with a larger error estimate?
[Response: Yes (although if you’re using annual averages, the autocorrelation isn’t very strong so the error estimate isn’t much larger). Put another way, the OLS trend estimate is unbiased.]
In the post “Autocorrelation” on this blog it is explained how to calculate the probale error of a trend estimate taking autocorrelation into account.
Link: https://tamino.wordpress.com/?s=autocorrelation
To do it in the most general form see Lee and Lund, Biometrika 2004.
The explicit formulas are quite complicated.
http://tinyurl.com/ylg6dus
Thanks Bart,
fyi your link doesn’t lead anywhere – I assume it’s supposed to be your post titled “Is the increase in global average temperature just a ‘random walk’?”…
Hahaha,
I love it how you copy-pasted the first ten pages of an undergraduate textbook in Time Series Analysis, and ‘impressed’ everybody here with ‘astounding’ mathetmatical statistics.
[Response: It’s my own description. But it looks like since you couldn’t find fault with it you accuse me of copy-pasting. How flattering. It doesn’t speak very well of you, however.]
OK, lets get into the matter.
First off, I didn’t do any ‘cherry picking’.
In fact, YOU were the one cherry picking by using the BIC for lag selection in your ADF test equation. Any other other information criterion (and I bet you tried them all) in fact arrives to a larger lag value and subsequently fails to reject the null hypothesis. The reason I didn’t use the BIC, is because it arrives at 0 (yes, zero) lags in the test equation. I actually noted this in the comments later on, on Bart’s blog.
Look it up, down the thread (I used the AIC, there was a typo in the first post, that I corrected later on).
[Response: Hmmm… I used BIC because you said that’s what you used. In your first comment (I didn’t read all your comments at Bart’s blog, because frankly you don’t deserve the attention) you said you used SIC, which means “Schwartz Information Criterion” which is the same as BIC.
Now you say that was just a typo.]
What kind of an effect does using 0 lags have? Well, residual autocorrelation in the test equation that messes up the ADF test statistic. Higher lag selections successfully eliminate any residual autocorrelation. Remember why the ADF test is ‘AUGMENTED’? Exactly because of the autocorrelation problem.
Also, when using ANY other information criteria to arrive at your lag specification, fails to reject the null in the level series, using ANY alternative hypothesis (check that as well, master statistician). I.e. no intercept, intercept AND intercept with trend.
Try that again, and report it, will you?
[Response: Using many lags doesn’t establish that there’s a unit root, it just reduces the power of the ADF test. That’s why it can fail to reject the null, even when it should.
And the inclusion of all those extra variables in the regression is dubious. How robust is your result if it requires avoiding BIC for model selection?
But there’s an obvious solution to the problem of conflict between different model selection criteria. Avoid the problem of reduced power from using so many lags in the ADF by using the PP test. It too corrects for that nasty autocorrelation, but without cramming all those extra variables into the regression equation. Maybe that’s why according to Phillips (1988), it’s the clearly superior choice. And what does the PP test say? Reject the null. No unit root.]
Finally, you selectively quoted me there, I said ‘de facto bounded’ because the VARIANCE of the error term governing the random walk is FINITE. How hard is that to understand for somebody pretending to be a statistician? Simply calculating trends, in light of these test results is spurious, and you should know that (unless you were ‘self taught’ or something similar).
[Response: I quoted you. Plain and simple.
But if you want to claim that it’s “de facto bounded” rather than “bounded” — well, that changes everything.]
Look at the temeprature series over the past couple of thousand of years. Where do you see a trend? There is a cyclical movement, but a deterministic trend? Nope…
[Response: Have you lost your mind? Or are you trying to make yourself look like an idiot?
Of course there’s no trend over the last couple thousand years. Because we haven’t been screwing up the climate until the industrial age. That’s the point.]
I seriously have no time for this kind of amateur nonsense, as well as your lashing out at economics. Economists are at least concious of their unconsciousness. Less can be said about the likes of you.
I’m not posting here anymore. If you want to have a chat, go to Bart’s thread, and I’ll consider educating you (but given your unfounded arrogance, the chances are slim).
Good day.
[Response: In your previous comment here you asked to “keep it civilized.” But it turns out that you’re what is called a “sore loser.”]
Tamino: maybe you should write an undergraduate textbook in Time Series Analysis (if you haven’t already). I think it would sell better than most.
VS: maybe you should read an undergraduate textbook in Time Series Analysis…. or better yet, one on how to communicate effectively. This is not my field, yet I can follow Tamino’s arguments – but not yours. In the unlikely event you are right, nobody will ever know, because you can’t explain it well enough.
Didactylos, well I suppose the layers of bullshit VS heaps on could be responsible for diminishing the clarity of his arguments.
What Didactylos said.
over the past couple hundred of thousand of years.. not thousand of years…
[Response: Oh, well, that too changes everything.
You said you wouldn’t comment here again. Let’s go with that, K?]
“We know that humans aren’t causing climate change now, because there’s no linear trend in global temperatures over the past 200,000 years.”
The mind boggles.
Or more precisely, since Milankovich cycles drive the long-term picture, we can’t impose a change on top of those cycles.
That’s odd.
VS,
Let me get this straight: You reject BIC because you don’t like the results it gives? When I have an analysis where AIC and BIC yield different conclusions, what that tells me is that there is no objective criterion for preferring the more complicated model–and that usually means going with BIC, or in this case, no lag.
More fundamentally, you are looking at this problem in a way that utterly divorces the numbers from the reality that generated them. Looking at time series over the past 2000 or even 200000 years may be fun, but CO2 levels are higher than they’ve been in over 600000 years. Physics tells us that gives us reason to expect the past 150 years or so to behave differently.
Physics also supports a roughly linear trend, given the logarithmic forcing of added CO2 and the exponential rise in CO2 concentration.
So, as a physicist, what I take from your analysis is that if you make a bunch of silly, contrary-to-fact/physics suppositions, I get a result that doesn’t make sense. Duh!
The range from the sample is easily explained. If you look at the test equation for the Dickey-Fuller test, you see that it uses a lag, hence the first observation of your sample you cannot use (In this case the year 1880). If the author really insists that he did use this observations, he must have done something wrong. If VS would have downloaded the data in 2009, then of course the annual mean for 2009 could not have been computed yet, which explains why it is missing.
[Response: VS says he used GISStemp data 1881-2008. GISStep data start in 1880. That’s what you pass to the ADF test. You’re clutching at straws to imply that I “have done something wrong.” Lame.]
I downloaded the data myself (including the mean for 2009) and performed several DF-tests with a drift and a linear trend. The results really depend on the selection criteria one uses.The results I get are:
Lag selection Ho: unit root Trend variable p-value trend variable
(p-value)
AIC 0.4301 0.148415 0.0111
BIC 0.0001 0.239066 0.0000
Hannan-Quinn 0.4301 0.148415 0.0111
Modified Akaike 0.9246 0.119943 0.0928
Mod. Schwartz 0.8237 0.124735 0.0559
Modified H-Q 0.9246 0.119943 0.0928
As one can see, only when the BIC-selection criteria is applied, is the null hypothesis of a unit root rejected.However, looking at the residuals of this test equation, there clearly is autocorrelation present, which makes this test invalid (as explained in the above article). When all the other selection criteria are used, no autocorrelation seems to be present in the residuals, and the null hypothesis is not rejected. Now, I don’t believe that someone can write such a good article on unit root testing and subsequently fail to look at different selection criteria. Seems like the author was cherrypicking himself! :)
[Response: As I explained to VS, I chose BIC because that’s what he said he used. Now he says it was just a typo. But you want to accuse me of “cherry-picking.” Worse than lame: dishonest.
As for “there clearly is autocorrelation present” in the residuals, it ain’t so clear. There’s nothing until lag 4 and even that is weak — just barely above the significance level. Maybe that’s why BIC rejects it. But you guys would rather believe that global temperature is a random walk where the increments follow an AR(4) (or more complicated) model, than that it’s a trend due to rather obvious laws of physics? Weak.
You also fail to acknowledge that including so many variables in the ADF test weakens the test so much that it can’t negate the null even if it should. Unit root tests don’t establish a unit root; they succeed or fail at contradicting it. But you daren’t contradict the outlandish theory you prefer to believing the laws of physics.
And none of you wants to face the fact that the Phillips-Perron test accounts for autocorrelation just as well as the ADF test, but does not require all the extra regressors that weaken the ADF test. The PP test says: no unit root. But you won’t believe it, because you just don’t want to.
What hasn’t yet been mentioned is that the ADF test is already weakened by the fact that it assumes a linear trend, but the trend is decidedly nonlinear. But there are ways around that. They flatly contradict the notion of a unit root. Look for another post soon.]
What’s more interesting is that the deterministic trend comes close to being significant (Under some selection criteria it is, while under other it is not). This could indicate that both a deterministic trend and a stochastic trend could be present, a phenomenon called quadratic trending.
Last but not least, with all the economics ‘bashing’, I got one to:
“Why did God create economists? ………To make weatherforecasters look good!”
Time will tell whether climate science stands closer to physics or to weather forecasting!
[Response: Time has already told.
Like I said. Sore losers.]
The VS actualy wrote: “Look at the temeprature series over the past couple [hundred] of thousand of years. Where do you see a trend? There is a cyclical movement, but a deterministic trend? Nope…”
Oh. My. Gord.
The man is utterly ignorant of the Milankovitch Cycles.
Talk about the arrogance of ignorance.
We definitely have no time for his kind of amateur nonsense.
Yes, that seems to be true.
Oh, well, economics as a field seems to be fairly divorced from physical reality, how else can one believe in infinite economic growth on a finite world? :)
BICSICAIC(???)
OIC
PIC
Tamino,
Thanks for this great, simple, clear tutorial on testing for unit roots! This is going to be immensely helpful to me. Thanks much!
-BPL
Ray’s “utterly divorces the numbers from the reality that generated them.”
My favorite definition of economics.
Funny that all the skeptics go on about how climate science is gonna cost everyone so much. The brilliant models used of late by the banks have already cost upward of, how much already? Does anyone actually know within, say, 50 billion?
Why have economists, as a group, not foreseen and spoken against this, ahead of time?
Considering how much climate science bashing is organized and carried by actors claiming to attach importance to Economics, I think it is high time for a little Economics bashing. Its shortcomings are far worse, yet nobody is asking for the code and data, less it be all a massive fraud. How come?
It’s not like some of their predictions have not failed to materialize.
$3 trillion in the US alone.
Philippe:
There is actually far more truth to the “economists are physicists taking a random walk” remark above than some would like to admit.
As indicated here, “the Black-Scholes model marks the beginning of the modern era of financial derivatives.”
And as everyone now knows, derivatives played a starring role in the recent financial fireworks display.
Guess what the Black-Scholes model is based on?
The random walk (more specifically Brownian motion)
Unfortunately, as wikipedia points out
Actually, that’s not quite correct.
To be a bit more precise, it exposes the “used” to “unexpected risk” (several trillion dollars and counting), but the “user” of the model still gets his fee (and year end bonus, of course). ~@:>
Horatio expects that for many economists and financial “analysts”, Black Scholes is more than a little like a “Black Box.”
Simply plug in the numbers and see what (nonsense) pops out.
Horatio’s brother-in-law is a “financial analyst” who regularly uses Black Scholes in the Black Box manner.
Horatio knows that for a fact because Horatio once asked him about the underlying assumptions and limitations of the model and it was clear from the answer that he really had no clue.
VS says
I love it how you copy-pasted the first ten pages of an undergraduate textbook in Time Series Analysis, and ‘impressed’ everybody here with ‘astounding’ mathetmatical [sic] statistics.
Isn’t that what you call projection?
From which I quote:
Part of the answer lies in the close examination of the Wegman report. Surprsingly, extensive passages from Wegman et al on proxies have turned up in a skeptic text book by contrarian author Donald Rapp. And at least one of these common passages on tree ring proxies closely follows a classic text by noted paleoclimatologist Raymond Bradley, but with a key alteration not found in the original.
Lose the trailing comma from the link and this works:
——
More mistletoe sent.
Ya know, decades ago, they _told_ me I’d pay for it some day if I didn’t really learn statistics.
But they didn’t tell me I’d _like_ paying for it!
Thanks again Tamino.
VS says
Is that supposed to inspire confidence?
There are known knowns, and known unknown knowns, and unknown knowns, and the WMDs are north, south, east, and west of Tikrit and in the rest of the general vicinity.
Darn, that VS is thick. On Bart’s blog he’s now doing loads of handwaving (“I’m too busy to react, but I’ll do it anyway, and the PP test is not worth a reaction, or maybe it is, anyway, it is no good” (this is not a direct quote)).
The most amazing handwave of all? He is complaining about arrogance…
I certainly read a load of c**p these days on various blogs devoted to climatology related matters, but poster VC has been exceptional.
But then I never visit WUWT…
Lucky you. I think E.G. Beck himself put in an appearance there today. He was also over at The Air Vent, a blog I just wandered into for the first time and to which I have no intention of ever returning. As you would imagine in any thread where Beck is being hailed as a hero, the stupidity at AV was thick enough to cut with a chainsaw.
What’s all this anti-economist rage about?
Given the number of economists out there in academia and business, it’s telling that so very, very few of them have made idiots of themselves by claiming expertise in climate science and joining in with the flat-Earthers.
By and large it seems clear enough that most economists are acutely aware of the limitations of their field.
How would you physicists like it if you had to survey a bunch of molecules to find out what they planned to do, only to have most of them change their minds anyway, and the government restructure the laws of physics because of some opinion poll?
A bit of empathy would not go astray.
Gaz: genius. Stole that for my blog.
You’re very welcome!
Well Tamino, just gotta say, I didn’t understand a thing you posted, but thanx anyways!
This is totally off thread but not all economist believed that SAY’S law would go on forever.
Once when I asked why economies can’t grow forever I was refereed to the physics department
Just saying that their not all scum of the earth – thanks for a great article
Economists are at least concious[sic] of their unconsciousness.
I’m pretty sure that means living in a dream.
Posted over at Bart’s place:
I’ve been doing some not terribly deep thinking about the implications of the “random walk” theory of climate change.
Now, as VS asserts, any changes in past global temperature and the current change in global temperature are due to random walks, then given a suitable length of time shouldn’t some rather improbable realizations of this random walk have happened? Given 4.5 billion years, which is a very long period of time, shouldn’t the Earth have had a realization of the random walk which leads to Venus like conditions? Now granted, my knowledge of statistics is related only to the evaluation of the odds of filling a poker hand vs. the odds being offered by the pot, but I was pretty good at that, and my gut can smell a bad hand when I see it.
Another thing that bothers me about VS’s arguments is that climate models are “phenomenologically based”. I take this to mean that they are statistical models. He based this “argument” on the parametrizations used for subgridscale processes which are used. Now in the last paper I read on GISS Model E, this was around 6 parameters, all of which were based on experimental or observational evidence. The vast majority of the model is based on physics and this holds true for all of the climate models in use. Some are better than others, but the fact remains that they are based on the physics of climate processes and not statistical relationships.
So what do you say, BS, oops, VS?
Sorry, for the OT comment, but have you seen this latest nonsense?
http://www.worldclimatereport.com/index.php/2010/03/02/most-of-the-observed-warming-since-the-mid-20th-century-likely-not-from-human-ghg-emissions/
Will it ever end!?
[Response: This is absolute proof that the “worldclimatereport” people will say anything, with no regard for truth at all, to discredit global warming. Pathetic.]
Isn’t it just a deuced shame that given such a seminal work as this, appearing in such a prestigious, nay world-reknowned forum as the worldclimatereport website, that technical difficulties prevent the rest of the knowledge base of climate science from provide peer review feedback?
Think of the plaudits and accolades that WCR is missing out on…oh, the inhumanity of it all!
Perishing the thought,
Daniel the Yooper
Hey, this is just as good …
Just in time for spring training!
World Climate Report is just … weird.
It’s very odd that when those people are talking about AGW they seem to forget that water evaporates faster when it’s warmer. It almost appers so they haven’t cooked anything ever (an I mean literally, not metaphorically) for themselves.
Methinks WCR cooks up a lot of stuff.
Very selective with the ingredients as well.
VS:
That’s nonsense. In fact, over 150 years, the “bound” is probably going to be more stable than over 100,000 years. The “bound” is simply equilibrium temperature, determined by the laws of physics, solar irradiance, albedo, emissivity, etc.
It’s ridiculous to suggest that the laws of physics don’t work over a period of 150 years, but they do work over a period of 100,000 years.
So that’s the end of VS, I guess.
At Bart’s blog VS has responded (14:59 GT + 1)in a more than 2500 words comment:
[Response: Seriously, folks, VS and his theories don’t deserve the attention.]
These two short “South Park”-style videos – although targeted at at a different “debate” – …well, the “detective” immediately reminded me of VS, especially when he pulls out his “killer-trump-card-to-end-the-discussion” argument each time and then walks away:
“What do you mean it’s not science? I carefully analyze the data using a highly sophisticated algorithm developed by information theorists with PhD’s in mathematics and distinguishing between undirected and directed causes through a very important step in the process that mainstream detectives completely overlook.”
Seriously, at least have a quick look at the first one. It’s quite apropos. ;)
Oh, Snap!
Yeah, but a lot of people would learn from a further take-down.
One thing I note is that he’s using his analysis of the data from 1880-present to claim that an OLS fit from 1975-present is invalid.
ISTM that if the basis for rejecting the appropriateness of an OLS fit for that time period is that the data is non-stationary, then his attempt to show that the time series is non-stationary should be for that timeframe, not for a timeframe that includes a whole bunch of years before which the CO2 signal began to emerge.
Or for 200,000 years as he so coyly points out shows no trend due to anthropogenic sources of CO2 …
Something changed, after all, in the mid-70s, and physics tells us what changed …
Not enough time for reading the complete text and comments. The problem can also be handled by the method of sequential tests as done by Wald (1947). Sequential analysis. New York: Wiley. The problem may be that successive observations in time series are not independent (correlating epsilon terms). See for this problem Gosh (1967) in the Journal of the American Statistical Association (62). These references are a bit out of date because I worked in this field in 1991 for the last time.
Perhaps that’s because they fear the loss of corporate profit more than they fear danger to the health and welfare of humanity.
Or perhaps it’s because the learned how to do the maths the economic way: without any reference to reality…
What does everybody’s low opinion of the economy and its various -ists have to do with anything?
Obviously, global temperature cannot be a random walk according to its strict definition. But it is highly autocorrelated and could be close to a random walk. If we regard global temperature as a random walk, which is what it appears to be over the last 150 years [edit]
[Response: Bullshit. It doesn’t.
I’ve already heard way too many faulty opinions about this; I’m not interested in adding yours to the list.]
Tamino, I think you are being a bit unfair on David here. You are aware of his 1997 Nature paper?
[Response: No I’m not. But I am aware that global temperature is not a random walk. If he wants to say, “It’s sure as hell not a random walk but some ideas related to that may be insightful,” that’s one thing, but when he says that’s “what it appears to be over the last 150 years,” I’ll call it as I see it: bullshit.]
Tamino, VS is still VSing all over the intertubes. He recently made a cameo over at RC, bragging about his “victory” over you and saying that, no, actually he quite liked the brand new and fully functional orifice you ripped him.
I’m not sure why it is so hard for these guys to see that CO2 is in fact a greenhouse gas. If their free-market ideology is really so feeble that it can’t deal with reality, I’d think it was time to look for a new, more robust ideology–maybe pragmatism.
One of the characteristics of a random walk is that … well, it’s random.
Well, except that his distance seems to be constrained entirely to the imaginary axis.
> “worldclimatereport”
Knappenberger (sigh): his “New Hope Environmental Services is an advocacy science consulting firm that produces cutting-edge research and informed commentary on the nature of climate ….”
David Stern // April 22, 2010 at 1:05 pm — Very easy to explain the last 13 decades of the instrumental record:
http://www.realclimate.org/index.php/archives/2010/03/unforced-variations-3/comment-page-12/#comment-168530
in which the CO2 forcing formula is missing a right parenthesis and should read
AE(d) = k(lnCO2(d-1) – lnCO2(1870s)) – GTA(1880s)
Maybe a better way to state this is that it is a scale issue. Anyway, the reason the series looks like it has a stochastic trend in this time frame is because of the anthropogenic forcing which certainly looks like it has a stochastic trend over this time frame.
David Stern has dome worthwhile work on the statistical analysis of climate data, e.g. http://www.sciencedirect.com/science/article/B6V8V-4HS39MT-1/2/a28b92360d6f6d6005c5aa20b4bda38e
and more here:
http://www.sterndavidi.com/topics.html#cli
I think Tamino misunderstood where David Stern was coming from, perhaps. He’s supporting VS’s insinuation that the presence of a unit root making the temperature record over a particular time frame looking stochastic “proves” that CO2 has no real affect on global temps.
In fact, Stern found out about the thread at Bart’s apparently because someone cited his recent Nature paper in opposition to VS, and VS hand-wavingly “disproved” the paper (chuckle chuckle) …
As can be seenhere, a true random walk exhibits “stochastic self-similarity”:
> the estimated climate sensitivity to a
> doubling of carbon dioxide is 4.4 K.
Any chance you can pull in some of the other climate scientists and talk about this in a thread? It’s the sort of thing ordinary readers can follow and learn a lot about how science is done, how different estimates done different ways by different people are contributing to our overall knowledge of the range of possibilities, rather than negating one another.
Hank Roberts // April 23, 2010 at 4:04 pm — From where are you quoting? I seem to have missed it.
Sorry, that bit about climate sensitivity is from David Stern’s paper, that Bart linked to just above.
Probably considered then in this review paper on climate sensitivity:
Click to access knutti08natgeo.pdf
Another good one just out (in English)
> probably considered in [Knutti 2008]
Nope; it’s from 2006.
Knutti & Hegerl (2008), the review paper in question, includes refrences dated at least as late as 2008 (but also “in press”). But indeed, as best as I can make out, Stern’s paper is not referenced.
And a callout to David Stern over at RC as well:
http://www.realclimate.org/index.php/archives/2010/04/krugman-weighs-in/comment-page-7/#comment-172088
It would be interesting to see the result of the same methodology that VS uses to describe the global average temperature as a “random walk”, against a known trend. A good example would be the daily maximum temperatures for each day in a given location for the months of March and April. It would be interesting to see if that emerges as a random walk as well.
I do not know the methodology VS uses, can someone else help out?
It obviously cannot be just a random walk. Basic physics says it has to be of the form
Yt = Yt-1 + I – R(Yt-1)
where I is the insolation and R is the radiation function, and each of I, R includes random components.
The question becomes whether it is possible to determine whether those random components are independent from one year to the next or betray a trend. Trying to determine that without the right basic form of the equation is fruitless.
Could use Bayesian estimation or MLE, right? Need to supply candidate forms for the way the parameters change over time, plus candidate distributions for the remaining random (year-to-year independent) elements.
I dare anyone who believes that the observed climate changes are a “random walk” to stand on their principles when their child is admitted into hospital with a rising fever. “Oh it is just a random variation, there is no real cause for the fever, just take your child home, nothing to worry about”. Would the “random walker” trust their child’s life to their theory?
The nasty criticism of economists in the original post is wildly off the mark. Asserting economists are just plain evil, caring more about corporate profits than human welfare, should be a non-starter in reasoned discussion, echoing the denialist claim that climatologists engage in widespread scientific fraud just to get more research grants. And of course `economists can’t even forecast macroeconomic aggregates!!’ should also be a non-starter among statistically literate people, as it is a baseless criticism for much the same reasons that deniers pointing at random short-term variation in temperature as evidence against global warming is baseless.
The original post, ironically, presents a discussion of temperature using methods drawn from the econometrics literature. The main point seems to be that temperature is bounded and therefore cannot follow a random walk.
But the process suggested as an alternative includes both drift and a secular trend so it is also unbounded, and therefore this process also must be wrong in the narrow sense the original poster apparently has in mind.
All models are wrong, some are useful. Here, wrong models with unit roots are sometimes more useful than wrong models without unit roots.
[Response: The “unit root” model fails — standard tests for unit root. It’s not only wrong, it’s useless.
The depth of your foolishness is revealed in the claim that “the process suggested as an alternative includes both drift and a secular trend so it is also unbounded.” You really don’t get it. The process suggested as an alternative is not a time series model at all. It’s that global temperature responds to external forcing via the laws of physics.
That economists are so eager to model global temperature by simple statistical models which fail simple statistical tests, are contradicted by observed data, and contradict the laws of physics — in spite of utter, astounding ignorance (in all senses of the word) of those laws of physics — is evidence of culpable arrogance in the extreme. I suggest you return to predicting 12 of the next 3 recessions.]
That gets my vote for the single funniest thing I’ve seen you say, Tamino!
My ribs still hurt from laughing…
Tamino, it’s possibly corrrect that a disproportionate number of the people using fancy-looking statistics to try to deny something or other about climate change are economists.
However I’d suggest that this is because a disporportionate number of the people who have had exposure to statistical analysis are economists who’ve had some (at least introductory) education in econometrics. This does not mean a disproportionate number of economists are climate change deniers, just that those who are will be more likely than other denialist types to throw some statisticky-looking blather at the argument. (I mean, Americans are much more likely to accidently shoot themselves than the English are, but that’s because Americans are more likely to own guns, not because they’re clumsier than the English.)
With this in mind, I would ask you though to reconsider your tendency to denigrate economists generally.
If I had to make a bet, I’d say people currently employed as economists would be very much more likely to accept the reality of anthropogenic global warming than the general public.
I mean, people like Stern and Garnaut are hardly fringe-dwellers, are they?
This story formed the basis of a post by Tim Lambert at the Deltoid blog:
http://www.thebigmoney.com/articles/hey-wait-minute/2009/02/11/surprise-economists-agree
I talk with quite a few economists and I don’t detect any signficant tendency to ignore scientific reality. By and large, they are the people who are doing the work trying to design solutions to the problem.
Being well aware of the limitations of their own profession (that well-known joke about predicting recessions is attributed to Paul Samuelson, a Nobel Prize-winning economist, by the way http://www.great-quotes.com/quote/66016 ), the great majority of economists would be very reluctant to go blundering into someone else’s field.
OK, once in a while one crops up, but claiming “economists are so eager to model global temperature by simple statistical models which fail simple statistical tests” as if it’s some widepread tendency of economists to make prats of themselves is just friendly fire.
Please, train your guns on the enemy.
Gaz,
Speaking as a denizen of yet another field (physics) that produces a seemingly disproportionate proportion of denialists who should probably know better, I have to admit to wondering whether physics education might not be failing in some critical way. How do people manage to get a PhD without understanding that those who publish most often and who are cited most often in a field are overwhelmingly likely to be the very ones who best understand that field? That’s so basic to scientific method that one cannot claim to be a scientist if one doesn’t understand it.
In physics, we suffered another onslaught of Philistines–when they were trying to build the Superconducting Super collider. There were a lot of physicists outside of particle physics that crawled out of the woodwork to decry the machine–as if the money not spent if the thing were cancelled would magically find its way into their research budgets. In the end, all that happened was passing scientific leadership to Europe. It is bothersome that there are so many scientists out there who don’t really understand science.
Ray, there are certainly reasons why one might wish and even hope that science would be different–especially now, when accurate modeling of the physical world (in both formal and informal senses) has real survival value.
Yet, perhaps science is close to many other disciplines (mine among them) where skill in normal professional activities doesn’t correlate all that closely with ‘philosophical’ understanding of the deep discipline.
Gaz, if you’re subsscribed to this thread: I’m possibly putting your quote at the top a chapter of my thesis (next to Feynman!), thought I should try and get permission (and possibly your full name?) Are you still here?
My supervisors might not let me of course.