
As many of you know, nine months ago I predicted the minimum Arctic sea ice extent for 2011 would be 4.63 +/- 0.9 million km^2. I’ll update that prediction using more recent data from NSIDC.
The earlier model predicted the September average using a model based on time evolution. In particular, it used a quadratic model:

Fitting the model to observed September averages, then extrapolating one year into the future, gave the prediction 4.63 million km^2.
We now have monthly average data for both extent and area of sea ice through the first six months of 2011. Can these data improve the prediction? I first tried including an additional variable, the monthly average extent for June:
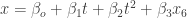
where 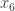
Then I tried using the June average, not of extent but of sea ice area:

where 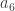
Finally, I tried a model using both the area and extent of the preceding June:
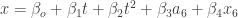
Both new coefficients are statistically significant, and the AIC for this model is the best yet (but not much better than the preceding model). Its prediction is for an upcoming September average of 4.66 +/- 0.66 million km^2, which is only slightly different from the original prediction of 4.63 million km^2.

RealClimate recently posted a discussion thread for Arctic sea ice. Several of the reader comments suggested that this year we’re likely to break the remarkably low 2007 value for sea ice extent minimum. Most of these prognostications are based on the fact that at present, extent is at an all-time low for this time of year and is still dropping fast (daily extent data from JAXA, 2011 in red):

However, the coefficient of June extent wasn’t statistically significant. Furthermore, the June area is quite low, but not an all-time record for this time of year (daily area data from Cryosphere Today, 2011 in red):


It seems to me that the final model (using both area and extent from the preceding June) gives the best prediction, so I’ll go with 4.66 million km^2.
I’ll also point out that even with this model, the 95% confidence interval is still quite large (+/- 0.66 million km^2). So according to the model, it could be as low as 4.00 million km^2 or as high as 5.32 million km^2 and still be within the 95% CI. Clearly, what happens with the weather over the next few months will dramatically affect this year’s minimum Arctic sea ice extent.
Just as clearly, over the long term Arctic sea ice will continue to disappear. The trend continues.



Well done, Tamino. Top notch.
As Mike Serreze pointed out on the RC thread and I have been saying for a week on the Arctic Sea Ice blog, there is a shift in weather patterns taking place. This is already being reflected in the daily extent numbers as reported by IJIS. It remains to be seen if things stay this way. If they do, there could be sustained transport of ice through Fram and Nares Strait. This could have an effect in the final phase of the melting season.
But that’s mere speculation. For now extent decrease is going to slow down, and the trend line will probably creep closer to that of 2007.
Did I say Mike Serreze? I meant Mark Serreze, of course.
Hi, Only thing that matters is the minimum and thickness nothing else and I do remember that during the MWP that Eskimos visited Scotland.
[Response: Never heard that.]
Kidding, I hope? Personally, I suspect it’s ice *volume* that matters the most, and it’s dropping like a rock as far as we can tell right now.
Well her you go
http://www.carc.org/pubs/v15no5/5.htm
Very interesting. . . though I didn’t find anything about Scotland in there. . .
According to Lamb’s “Climate, History and the Modern World”, there were a number of reports of stray Eskimos arriving in the Orkney Islands between 1690 and 1728, and once on a river near Aberdeen. This is very much in the Little Ice Age not the MWP.
Fascinating, Phil. Are these reports credible? How did the Eskimos get there, one wonders, and how on Earth did the locals figure out they were Eskimos? (Well, maybe some of the boys from the Isles went a-whaling betimes, and could recognize a Greenlander when they saw one?) Hell of a voyage in a skin boat. . . .
And if any of this is true, what became of those folks? What a story they could tell!
Please forgive me if this question exposes my ignorance, but could volume estimates be incorporated as you have incorporated are and extent, and do you think it would be useful? If not now, maybe after a few years of cryosat data?
[Response: Probably yes, and that might be very fruitful. But only the numbers will tell. I plan to update this when the next month’s data is available from NSIDC, so maybe I’ll trying using volume numbers at that time.]
For me, as a layman, this graph says that “this year’s minimum volume is going to be about 2-3 thousand km^3″ below that of 2007” and that tells me that a few percent here or there won’t really make a difference compared to the 12-15 thousand km^3 minima of about twenty years ago.
Well Tamino, I think you are too high. I like the analysis where people looked at the
melt rate from here to the end of the season for the last eight years. If we get the melt rate of ’04, ‘ 07, ’08, ’10, then 2011 will set a new low extent record. If we get the melt rate of ’03, ’05, ’06, ’09, then 2011 minimum extent won’t beat the 2007 low. So based on previous melt rates from here, it seems as though dropping below 4.25 million is about a 50/50 proposition.
The other thing to look at is where the ice is this year. There is a lot of ice area in the seas where most of it will melt out. The Beaufort, East Siberian, and Greenland seas, as well as the Canadian Archipelago have a lot of ice that will almost certainly melt out by the minimum. Adjusting out this expected loss of extent, then looking how much ice extent must fall in the central Arctic Basin leads again to a likely chance of a new low extent minimum this year (lower than 4.25 million sq km).
The odds of the extent minimum being less than 4.63 million sq km is probably over 90%, since the loss of extent in the lower latitudes is almost certain, and that alone brings us to about 5.20 million sq km. Then if the central Arctic Basin loses more than 0.57 million sq km from this point, the minimum ice extent falls below your estimate. None of the last eight years have seen that low of an extent loss for the central Arctic from this point in the season.
[Response: Could be. I’m the first to admit that this simple statistical model is quite limited in its ability, and it certainly doesn’t account for a lot of factors (like geographic distribution and ice volume). My prediction last year using a similar method was very close, but that was luck. And my error bars are quite large.]
Hey, the comment Zinfan94 linked was from me! My 15 minutes have arrived!
Seriously, though, Zinfan–you are kind, but probably giving way too much credit by calling that an “analysis.” It’s like Tamino’s model only in that it _also_ doesn’t account for geographic distribution and ice volume. It’s unlike Tamino’s model in that my thingy doesn’t account for current area or even current extent (!), and involves no statistics other than a mean (with no characterization of the error) and a range (of an arbitrary and tiny data set).
It was fun to think about, but IMO there’s really no reason to think the situation will evolve from here in a way that’s bounded by what happened in the same date range in the last 8 years. There’s a very different starting point, for one thing. And there’s nothing to say that weather conditions will be similar to any of those 8 preceding years.
Kevin S. – I really am just bootstrapping off your idea. But instead of looking at the entire ice area/extent, I break the ice down roughly by location. I have noticed that is very difficult to melt ice north of 80N latitude in the heart of the Arctic Basin. If and when (in future years) this ice goes, it will likely be due to loss of the buttressing effect, and with favorable wind conditions that push the central Arctic Basin ice into the Fram Strait.
So what does the ice location distribution look like this year, compared to 2007? The guys at the Univ. Illinois keep a nice site showing high concentration (30% plus versus 15% plus used by most sites) ice extent maps. This site shows comparable maps for 2011 vs 2007 and this year shows very different geographic distribution. The melt in 07 came from the direction of the Beaufort, Chukchi, and East Siberian seas. The melt in 2011 is coming from central Siberia in the Barents and Kara seas. The blockade of ice that usually exists around Severnaya Zemlya is already gone this year, and the ice pack in the Arctic Basin has fallen back above 80N in many intrusions from that direction. There must be a lot of sea surface warming in those areas, which could drive the 2nd half seasonal melt. (Zoom in on both sites to see better detail.)
The big ice extent in the East Siberian sea and the Arctic basin extending down toward the Beaufort, Chukchi, and East Siberian seas will almost certainly be decimated as we approach the September minimum. So if we correct out for most of the lower latitude melting that is almost certain, then we can calculate an estimate of the minimum extent (less the Arctic Basin) and this is about 5.2 million sq km.
At this point, I can apply your technique of using melt from this point forward, but only to the Arctic Basin ice extent. Arctic Basin ice extent is roughly the same as last year, and we only need a fall of about 1.0 million sq km from the current extent in the Arctic Basin. Generally, this is the kind of extent loss we have seen in the Arctic Basin in recent years. So the minimum ice extent is almost certain to fall below 4.6 million sq km, and has about a 50/50 chance of getting below 2007.
Why? Because a lot of the “stubborn ice pack” near Novaya Zemlya is already gone this year.
If the wind and weather set up an Arctic dipole in August, then we could blow out below the 2007 minimum by September 1st.
One problem with your estimate is that by basing the estimate on June, it ignores the last 3 weeks of data. Visually (based on the JAXA plots), it seems that there is a period from April-June that is not very meaningful in where the ice extent will end up. This starts to change in the June – July time frame. I just did a quick comparison of the ice extent from June versus September compared to the most recent 30 days (June 20-July 19) versus September and found that the correlation coefficient moves from 0.34 up to 0.63. Your story might change if you based your model on the most recent 30 days.
Tamino, to follow up on the commenter who suggested volume data, you could use the daily (modeled) volume data available for download from the UW PIOMAS team here http://psc.apl.washington.edu/wordpress/research/projects/arctic-sea-ice-volume-anomaly/data/
You could then choose to work with some consistent average, say the average volume of days 181-200 from each year, and put that in to your basic quadratic-in-time function as the third element. Some playing around on my part finds a significant correlation between the PIOMAS July volume and Sept avg (or min) extent.
Please correct to her to here
Tamino,
Question for you. How do you get the confidence intervals for your predicted value? I mean you have to propagate the polynomial coefficient covariance matrix to a future time don’t you? If so, how was that accomplished?
[Response: You don’t propagate the covariance matrix into the future; the polynomial coefficients remain constant — that’s what the model is — and so does the covariance matrix. Instead you can define what I like to call the “uncertainty function,” a function of time which depends on the uncertainty in the polynomial coefficients. For a quadratic fit, it turns out to be a quartic function of time. And that’s just the uncertainty due to probable errors in the fit coefficients.
Then you add in the uncertainty due to plain old noise because the observed value jitters around the model values even if the model is, statistically, exactly correct. In fact in this case, the jitter due to noise overwhelms the uncertainty due to probable errors in the fit coefficients.]
“On August 21, 2007, the Northwest Passage became open to ships without the need of an icebreaker.”
read at climate progress that opening was not far away”
anyone taking bets on this year’s date,
Tamino without butting in i wish that all your great analysis and graphs could be placed into one peer reviewed paper each year, bloody sceptics, “taminos just a blog where is you peer reviewed science”
How well does your model work if you do without the trend terms, both linear and quadratic, and simply try to predict from the observational terms (June extent and area)? How about if you add more observational terms (winter maximum extent? previous summer minimum extent? lagged ENSO?)
I’ve read about Inuit kayaks, sometimes containing dead Inuit, reaching Great Britain by following along currents.
Unlikely to have happened in the MWP – the Inuit had to knock off the Norse in Greenland first, and that took a little while
Like the end of MWP.
Hi Tamino.
A paper on sea level rise was given prominence today in a certain newspaper. You know, the one that’s reached a score of 64 on Deltoid.
The paper concluded that there was a decelerating trend in sea level rise over the period 1940 to 2000.
Here’s the paper.
http://www.jcronline.org/doi/pdf/10.2112/JCOASTRES-D-10-00141.1
Maybe you could find the time to comment on the paper’s methodolody – 20 year moving averages of 4 long-running tide gauges, fitted with an order 2 polynomial.
There are obvious issues with the paper, eg it skirts around changes in the various forcings (anthro vs non-anthro) forcings in the 1st vs 2nd halves of C20, but I don’t think the author is trying to obfuscate, I’m just intirigued by the choice of statistical methodology.
Please keep up the good work.
Already done, see here:
https://tamino.wordpress.com/?s=dean+houston
[Response: That was a different paper. This is another one.]
Hank Roberts’s coment at RC is worth a read.
Tamino
Apologies for OT.
I wonder if you are able to help.
There is a little storm in the Australian denier press brewing stating that this paper shows the SLR acceleration is not happening the Southern hemisphere:
P. J. Watson (2011) Is There Evidence Yet of Acceleration in Mean Sea Level Rise around Mainland Australia?. Journal of Coastal Research: Volume 27, Issue 2: pp. 368 – 377.
http://www.jcronline.org/doi/full/10.2112/JCOASTRES-D-10-00141.1?prevSearch=%5BAllField%3A+watson%5D&searchHistoryKey=
I’ve had a look at the paper and some of the quadratic curve fitting looks a little odd.
Would you be able to have a look?
Thanks
Honestly, there was no comment from Gaz when I posted…!
Tamino,
Thank you for your response to my question above concerning the propagation of the covariance matrix. The motivation for the question came from my attempt to implement a Kalman filter for the purpose of tracking and predicting sea ice extent. I would be very interested to hear any comments you may have on this approach.
I had tried a polynomial filter over the full data set and computed the covariance matrix but was unsure how to use it with the predicted value so the question. The Kalman filter has a straightforward way of doing this because in the state space implementation the predicted state covariance matrix is propagated forward to the same time as the predicated state and that is what I used to determine the prediction uncertainty.
I liked your approach on this which was just to use the Sept sea ice extent data to predict the coming September value. It is a very effective method and only requires a one step prediction. The updates in the current blog entry have some interesting ideas too for sharpening the prediction.
The Kalman filter is very involved so a lot can go wrong. But anyway to briefly describe it the anomalies were computed using the entire 1978 through 2011 as the baseline, The measurements input to the filter included the anomaly, its velocity, and its acceleration. The latter two were formed by first and second differences in the month to month anomaly data. The measurement noise (uncertainty) matrix had to take into account the cross correlations in the measurements. The filter was linear in the sense that the filter states were the same as the measurements so was implemented as a 3 state constant acceleration estimator with a white noise jerk process noise model providing acceleration uncertainty. The update time was one month. As such it too was a quadratic polynomial estimator with some adaptation capability resulting from the process noise. The predicted extent was formed by summing the predicted anomaly and the monthly extent average. The extent prediction uncertainly was calculated from the RSS of the predicted anomaly standard deviation acquired from the predicted state covariance matrix and the standard deviation of the average monthly extent estimate. Filter performance was based on how well the filter reduced the measurement noise compared to the state noise.
To see how well the predictor worked the filter trained on data up through April 2011. A September prediction required 5 steps forward which was beyond the filters capability.. With no measurements from May to September the filter basically coasts the last filtered state (from April) and filtered covariance through 5 updates.
For one step prediction to May it predicted 12.92 million sq km with a prediction standard deviation of .359 million sq km. Its prediction for June was 11.675 million sq km with a prediction standard deviation of .62584 million sq km. May extent came in at 12.79 million sq km June at 11.01 million sq km.
So for one or two step prediction it seemed to do OK but the uncertainty will yield large confidence intervals. 5 months out to September yielded an estimate of 7.5 million sq km. with an uncertainty of 2.45 million square km.
With May data available the filter prediction for June improved to 11.34 million sq km with a prediction standard deviation of .354 million sq km. September’s prediction was 6.26 million sq km with a s.d. of 1.4 million sq km.
With May and June data available the July prediction is 8.95 million square km with a one s.d. prediction uncertainty of .447 million square km. Three months out to Sept the prediction is 5.47 million sq km with an uncertainty of 1.14 million sq km.
Just wondering. What is your prediction and confidence interval for July?
Anyway, I look forward to hearing any comments you or anyone else in the forum may have on the procedure or results discussed here.
Incidentally, this has been an extremely interesting and informative series of articles on Sea Ice Extent from the point of view of both time series analysis and climatology. The time and effort you put in on explaining and presenting these ideas is greatly appreciated. Also the commenters have provided some excellent links to sites and papers on Arctic Sea Ice.
Great minds think alike!
Is there a physical reason why including the sea ice area + extent in June should improve your model?
I’m not really happy with using a time trend to forecast ice extent because there’s nothing physical about it. It’s obviously just a proxy for the steady warming of the arctic.
I’ve been trying to develop a simple relationship between arctic sea ice extent and polar temperature. Unfortunately, It has been limited by the fact that I can only find annual polar temperature data (GISS, 64 to 90 deg N). The most appropriate monthly data I can find is for the entire northern hemisphere.
While N hemisphere seasonal temps and polar annual temps both loosely correlate with ice extent, neither does any better (or worse) than Tamino’s simple time trend approach. However there are some tantalizing hints that anomalous years like 1996 (large increase in September extent) and 2007 (large decrease in September extent) might be explained by summer polar temperatures (1996 was a cool summer in the N hemisphere and 2007 was a warm year at the poles).
Does GISS publish their monthly/seasonal zonal data anywhere?
Ernst K,
The best I’ve been able to do is what was referred to in earlier in the thread:
Use the current extent and work out the falls from the same date to the minima for previous years. Using JAXA’s dataset from 23/7/11 I get
2002 4321875
2003 4662187
2004 4149844
2005 4534531
2006 5065000
2007 4190781
2008 3843750
2009 4597656
2010 4247344
2007’s minimum was 4254531.
In essence what that method is doing is using the weather and ice conditions of the years 2002 to 2010 to estimate a range of probable outcomes for this year.
Trying to use just temperature in the Arctic has one main problem, the temperature can be raised by the presence of open water, which itself is due to reduced sea-ice. Furthermore it doesn’t take into account issue like cloudiness (which are related to the AO and AD modes), and ocean heat transport.
The best option is a model like PIOMAS, which I consider to be the best available. e.g. PIPS overprojects thickness. However even PIOMAS suffers from the major impact that weather has, so they use the weather conditions for the past 7 years to make 7 ensemble members, like the (admittedly far simpler) method I outline above. You may have seen the PIOMAS projection, but in case you haven’t it’s here:
http://psc.apl.washington.edu/zhang/IDAO/seasonal_outlook.html
Their forecast is 4.3 +/- 0.5 million square kilometers, the hindcast runs to the end of June, so the forecast doesn’t account for the rapid losses due to clear skies in early July. But it is in the same ball-park as Tamino’s stats.
Sorry to be so negative, the only positive sugestion I can make is Megan stone’s Doctoral Thesis: It may be of interest to you.
Click to access 10Jun_sTONE.pdf
I am glad someone with more skill is going down the route of a multiple non-linear regression model (following ;o) my example http://www.arcus.org/files/search/sea-ice-outlook/2011/07/pdf/pan-arctic/randles_panarctic_july.pdf )
For the August report, I have tried using various combinations of extent, volume, thickness and July decrease as well as area but didn’t find anything that reduced RMSE more than an average set of random numbers so have just stuck to using gompertz fit and area.
I am sure you have a lot more experience / ability to do this sort of thing than I have so any comments on the difference between our approaches would be appreciated.
I wouldn’t have a clue how to calculate an ‘Akaike Information Criterion’ but suspect it would be a significant improvement on my approach of comparing to several sets of random numbers to see if an extra data set provides significant improvement in prediction.
Should I leave this sort of thing to experts rather than having a go?
[Response: By all means keep at it. Your approach seems logical.
You can find out about AIC on Wikipedia. Numerous programs (including R) will calculate it for you automatically.]
Ernst,
UAH gives monthly t2lt temperature data for North Polar regions and also breaks this down between land and ocean. I realise you probably want SST / 2m height temperatures instead or perhaps other heights as well.
http://vortex.nsstc.uah.edu/data/msu/t2lt/uahncdc.lt
[Response: Note that the UAH TLT (and RSS TLT) data does not extend above latitude 82.5N.]