
Robert Grumbine has a post in which he takes an unusual look at global temperature data. I’m afraid I must take exception to his methodology.
He starts with the HadCRUT3v data set (and kindly provides his data as an ExCel file here). He then defines a couple of different versions of “climate normal” as the average over some particular time frame. In fact his first choice is to use the entire data set, for which the climate normal is just the data average:

Then he transforms the data values 
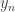

He then computes running sums of the cooling degree months to generate a new time series of accumulated cooling degree months; let’s call that 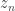
![z_n = \sum_{j=1}^n y_j = \sum_{j=1}^n \Bigl [ x_j - \bar x \Bigr ]](https://s0.wp.com/latex.php?latex=z_n+%3D+%5Csum_%7Bj%3D1%7D%5En+y_j+%3D+%5Csum_%7Bj%3D1%7D%5En+%5CBigl+%5B+x_j+-+%5Cbar+x+%5CBigr+%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
First of all we’ll note that 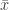
![z_n = \Bigl [ \sum_{j=1}^n x_j \Bigr ] - n \bar x](https://s0.wp.com/latex.php?latex=z_n+%3D+%5CBigl+%5B+%5Csum_%7Bj%3D1%7D%5En+x_j+%5CBigr+%5D+-+n+%5Cbar+x&bg=ffffff&fg=333333&s=0&c=20201002)
Let’s give a name to the accumulated sums of the raw data values 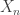

For instance, when defining the average using the entire time span Grumbine gets this for the accumulated cooling degree months:

and I get this:

They’re the same.
Later he uses a different time span to define “normal.” But that just leads to a different value for
My complaint is that it’s way to easy to see patterns in cumulative sums that really don’t mean anything. Suppose for instance that “normal” temperature was zero, and the deviations from normal were purely random numbers — plain old white noise like this:

If we then define “cooling degree months” as departure from the average value, and accumulated cooling degree months as the cumulative sums of those, we get what looks like an extremely strong pattern:

But the pattern really doesn’t mean anything at all. By construction, the time series is just random noise.
The root of the false appearance is that the time series of cumulative sums has extraordinarily high autocorrelation, to an extremely high lag. Here’s the sample autocorrelation function for the random-noise cumulative sums:

Note that the autocorrelation is both extremely high, and persists as long as lag 600 months (50 years!). That’s just the nature of cumulative sums. And that’s for random noise which is white noise, i.e., which isn’t already autocorrelated. Actual temperature values already show autocorrelation, which leads to even stronger autocorrelation in the cumulative sums.
In fact we can generate random numbers with autocorrelation similar to the noise (not the signal!) in global temperature, like this:

Then we can compute accumulated deviations from average just as before, and we get this:

Note the extremely strong appearance of a powerful signal. But again, by construction the data are just random, pure noise.
There are ways to deal with cumulative sums, and in some (rare) circumstances it is natural to analyze them. But this isn’t one of those circumstances. There’s no information in the cumulative sums that isn’t already in the original data, and you don’t need the cumulative sums to glean insight about what the trend is doing — that too is clear from the original data.
In fact computing cumulative sums is a very dangerous approach to analyzing data, the autocorrelation is too strong and the likelihood of deducing patterns where none really exist is just too high. So I recommend against it, very strongly.



What? You are criticizing “our” side? Next thing you’ll be accused of scientific integrity. Of course, pseudo-skeptics do this to – for instance,
… um…
someone help me here?
On your own, dude.
Most of the problem, I think, is the very limited definition of “normal” – that a good normal will feature multiple fluctuations around zero in his cumulative sum.
This is consistent with most people’s ideas about randomness: an instinctive sense that things should regress rapidly to the mean. This actually implies anti-autocorrelation in the signal.
Such an expectation is troubling enough when trying to analyze a time series with no long term trend, as you have shown. When you’re looking at a time series with a clear trend his definition is doomed to fail. A trending series will almost never look normal, by this definition.
It would perhaps be interesting to compare the 95% confidence range of cumulative sums of noise with and without autocorrelation. I assume the dipping curve in your first two figures would sit well outside of that.
Although I’m not sure what that could add that other analysis couldn’t.
The discussion reminds me of Klaus Hasselmann’s 1976 stochastic climate model (http://www.aos.princeton.edu/WWWPUBLIC/gkv/history/Hasselmann76.pdf)
where he develops the theory for how random weather noise gets “integrated” by the ocean which then causes multi-decadal variability without an explicit forcing. It seems analogous to cumulative sums.
Yes, first order integration – always prone to instability…
What is more, the temperature series is itself the _result_ of a process that includes integration of net heat addition.
[Response: Only with the sloppiest interpretation of words can it be called an integrative process. And since heat loss depends on temperature as well, global temperature is certainly *not* a cumulative-sum process. That’s just the “random walk” fallacy again.]
Phil Scadden, Roy Spencer has at several occasions corrected misunderstandings of the science by other “pseudo-skeptics” on his blog. Even WUWT has done it. A couple of examples:
http://www.drroyspencer.com/2010/07/yes-virginia-cooler-objects-can-make-warmer-objects-even-warmer-still/
The real challenge isn’t saying one on your side is wrong, it’s admitting that some of your opponents may sometimes be right.
So when you do things to data and see interesting patterns, you need to be very honest with yourself as to whether it means anything or not…..
Typo alert: Change “My complaint is that it’s way to easy to see patterns” to “My complaint is that it’s way too easy to see patterns”
Good warnings. I disagree (you’re not surprised) about the lack of reason to consider cumulative sums. Hasselmann, 1976 is one part of that. Also recall that I come to climate from the ocean and ice side of things — components of the climate system which are integrators. I take up things in more length at http://moregrumbinescience.blogspot.com/2011/08/is-it-really-normal.html
One possible outcome of more complete consideration of both the statistics and the physics is that we have to give up on the idea of there even being a climate in any objective, noncircular, sense. Or perhaps one can define an objective climate, but it’s impossible to find a ‘normal’ climate.
A request to both Robert and Tamino — could you as you go along make occasional reference to this practical application of the questions?
http://www.good.is/post/what-s-normal-weather-is-about-to-officially-change/
January 18, 2011
“… the National Climatic Data Center has been gearing up to announce new definitions of “normal” weather conditions for 10,000 regions across the country. And these new “normals” are going to be a lot warmer than the current definitions….”
better link: http://www.ncdc.noaa.gov/oa/climate/normals/usnormals.html#CORENORMALS
Tiny remark: shouldn’t the indices in the sums in equation 3 (and 4, …) be j instead of n?
so eg
z_n = \sum_{j=1}^n y_j
instead of
z_n = \sum_{j=1}^n y_n
and so on for the other equations.
[Response: You are quite correct.]
I love it when subscripts speak up for themselves when they feel ignored. Good job j!
Here is a link to a very interesting article in the most recent edition of the Bulletin of the AMS titled the Definiton of the Standard WMO Climate Normal by Arguez and Vose of NOAA. Not sure if this is accessible to non-members but I thought it was.
http://journals.ametsoc.org/doi/pdf/10.1175/2010BAMS2955.1
The WMO has previously recommended that countries up date their climate normals every 10 years. They want that update more frequently and possibly with a different algorithm than the 30 year average because of the problems associated with the non-stationarity of climate time series which has to be accounted for.
Tamino, did you read this article and if so, what are your thoughts on it?
Thomas – good points. And it does Spenser credit. I have pointed skeptics to Spenser’s article as it is more convincing coming from a known skeptic. I have to admit to being flabbergasted that Watts managed it – perhaps volcano CO2 is too laughable.
OTOH, the claim that greenhouse effect violates the second principle of thermodynamics is so outlandish that any people with an undergraduate course in physics *has* to correct it. Dr Spencer did that effort (as well as other people).
Notice however that, when Dr Spencer tried to correct that false idea, he was immediatly swarmed by a hord of angry commentators – and even Mr Monckton, who tried to help him, was accused if I remember correctly “a liar” :]
Funny, I was just ‘debating’ that G & T meme about 45 minutes ago. . . again, without any hope of convincing my opponent, but just keeping the record somewhat straight.
Hank : I’ll be picking up that point more in a while.
pjkar: I did see that paper ( not your question) and it has emboldened me regarding looking at/for normals. It won’t be the cumulative degree business at hand, but I do expect to be publishing some new ideas on climatology for sea ice and for sst.
Hey Robert,
I was intending to post that at your site as well.
“I do expect to be publishing some new ideas on climatology for sea ice and for sst.”
It will be interesting to see what you come up with.
You’re original post and Tanino’s response brings up the subject of climate normals up at a time when, as the AMS article shows, the methods of generating current climate normals is under question. These threads are the reason the AMS article caught my attention. So I appreciate you starting it off.Its a topic of great interest.
Good post. However, I would take exception to the statement “… in some (rare) circumstances it is natural to analyze them. But this isn’t one of those circumstances. There’s no information in the cumulative sums that isn’t already in the original data…”
I would argue that the relevant circumstances are not in fact all that rare. You can find a number of mechanisms in plant biology for example, especially those related to phenology/ontogeny, where cumulative heat or cooling sums are quite important. And I think your last sentence in that quote, while correct, misses the point that we transform variables all the time in order to make them easier to interpret or use, for our purpose at hand.
> plant biology … phenology
If biologists have data and could arrange to work with Tamino to write this kind of thing up, please put up a tip jar for encouragement.
I think a good clear assessment and explanation of phenology statistics would encourage the many individuals collecting local observations. I haven’t seen a good writeup; if I’ve missed it, a pointer and thread by Tamino on the subject would be welcome.
Various projects are out there. A look (maybe an invitation to the groups doing them) at their ability to tell us something would be valuable. If there are flaws in the data collection being done, improving that would be good.
http://www.google.com/search?q=phenology+migrations+bud+timing+spring
I don’t know that there are outright flaws, but there’s certainly a basket load of potential issues to be aware of, including things like genetic variability, physiological acclimation of clones, choice of event onset/finish vs peak, population size effects, changing observer bias and things like that. The people doing this work are of course, aware of all of these, and others.
PS, here’s one from the first page of that Google search — full text available:
Tree Physiology 27, 1019–1025 2007
Temperature sum accumulation effects on within-population variation and long-term trends in date of bud burst of European white birch (Betula pendula)
treephys.oxfordjournals.org/content/27/7/1019.full.pdf
“… Bud burst can be accurately predicted by the date when a threshold value of temperature sum in spring is reached (base temperature +5 °C). Based on this temperature sum and past temperature records, we estimated the trend in date of bud burst. The linear trend estimate based on the years 1926 – 2005 is an advancement of 1.2 days per decade (95% confidence interval, ± 0.7 days), which is much less than that predicted by time series based on coarser time intervals. We conclude that, because of large interannual differences, and large annual within-population variations in bud burst, estimates of bud burst date based on measurements made over a period of only a few decades are unreliable….”
A better search:
http://scholar.google.com/scholar?hl=en&q=phenology+migrations+%2B“temperature+sum”+bud+timing+spring
Usual caveat, restated from time to time; I know nothing about this stuff other than what I read in just poking around. Could well be the statistics used in this sort of study are well described and understood, but not published where a superficial scanner like me would stumble on the article. If so, a pointer to a good writeup would be welcome; I’d love to see all the various phenology/migration/springtime groups collecting data all have a common resource for their data analysis.
Nature, biology, is the most sensitive thermometer/climate-ometer around, if we know how to understand what’s happening in the details.
Hank, try google scholar for the likes of Tim Sparks, David Roy, Thackeray et al., for UK research – plenty of citizen scientists here & also some good long-term records (eg Marsham estate, BTO nest records, Wytham woods, Rothamsted insect survey, Fitter & Fitter’s first flowering dates, continuous plankton survey, etc. etc.). Also look for BICCONet, CEH & LWEC for some pointers to current research.
“. . . superficial scanner like me. . .”
On the contrary, Hank, you are (according to my observations) an unusually ingenious and resourceful scanner.
I’ve taken up some consideration of how random we can take climate to be. There’s some interesting room for more Tamino-caliber examination of statistical concerns. As usual, I took the simple approach. But I think the conclusion is that although we do indeed want to be cautious about cumulative sums, those concerns need not prevent us from trying to find a ‘normal climate’.
http://moregrumbinescience.blogspot.com/2011/08/is-climate-random-walk.html
I don’t know, on reflection something is bothering me on this. Your fourth graph down is simply one realization of an accumulated white noise series, is it not (and same for last graph, for an autocorrelated one)? If you run 1000 simulations, you’re going to get all manner of patterns, and the chance of seeing the observed one, by chance, is indeed quite small. Each run will give something that looks like a false signal, but the ensemble will not–and it is against that ensemble that Bob’s cumul. sum should be compared. What am I missing here?
[Response: The real world is only *one* realization of the randomness in the climate system. Therefore we cannot expect it to show the behavior of an ensemble of systems. James Annan has emphasized this regarding climate models — and indeed the ensemble average of a large number of model runs usually shows far less natural variability than is realistic, even when individual runs do exhibit realistic natural variability.]
Right, I understand that a single run can never show the behavior of an ensemble, by definition. What I was trying to say is I don’t get why you can’t do a straightforward simulation-based test, simply placing the realized situation in that context, white noise or red. The chance of getting Bob’s U-shaped pattern, is then still (I’m guessing), very small. It has to be–there’s an actual trend embedded in it, whereas the simulations have no such.
There is no topic in all of statistics more difficult, poorly explained and indeed, maddening IMO, than topics related to the effect of autocorrelation. I once went all the way back to the original papers by Pearson (or Gossett?) over 100 years, and still couldn’t follow it. It seems to me that at least part of the problem is people confusing ac in the response variable, with ac in the *residuals* of the response var., among other things.
An article on bad analysis using cumulative sums in hydrology. Not good for temperature, not good for precipitation. http://www.ncbi.nlm.nih.gov/pubmed/15584306
Hi Bob,
It’s been a while. I have used CUSUMs in several studies. In all of the comments on this web site, key issues regarding CUSUMs appear to be missing. First, CUSUMs were originally developed for quality control applications in engineering to detect change points in manufacturing processes (see “Detection of Abrupt Chahges: Theory and Application” by Basseville and Nikiforov where the application of CUSUMs to change detection is discussed in great detail). The signal-to-noise improvement for detecting small changes in a process is usually quite significant. I have used this technique for detecting regime shifts in SST data and it works extremely well for this application. The problems arise when one tries to interpret the large scale changes that invariably occur in CUSUMs. The problem of serial correlation is insidious and rears its ugly head as red noise in the frequency domain. I could go on but it was delight to accidently run into this topic on your web site.
Cheers,
Larry
Hey Larry,
Good to see you! See my blog for more comments. And please do email me at my work address or bobg at radix dot net. I have a paper in progress I think you’ll find interesting. http://moregrumbinescience.blogspot.com