
In the last post we showed how Harold Brooks has applied a 1st-order Markov Chain model to the phenomenon of a significant tornado day (“STD”), in particular to explain the frequency of occurrence of long runs of consecutive STDs. An STD is defined as any day with at least one (possibly many more) tornados of strength F2 or greater (on the Fujita scale).
The 1st-order Markov model did a good job, whereas a bare-probability model doesn’t. In the bare-probability model, the probability that any given day is an STD can depend on the time of year (May is the peak time of year for tornado probability), but does not depend on whether previous days had significant tornados. However, there are too many long runs of consecutive STDs (as many as 9 in a row in the data used by Brooks, as many as 12 in a row in the NOAA-NWS data) for the bare-probability model to be correct.
In the 1st-order Markov model, the probability that today is an STD can depend, not only on the time of year, but also on whether or not yesterday was an STD. If it was, then the probability that today will be an STD is enhanced. So this model has two probabilities (both of which depend on the time of year): 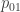

While the 1st-order does much better than the bare-probability model, the observed number of very long runs is still a bit more than the model indicates. Therefore I decided to explore another possibility — you may already have guessed that I looked at the 2nd-order Markov Chain model.
In the 2nd-order model, the probability today will be an STD depends not only on the time of year, but on whether or not the previous two days were STDs. There are four possible states for the previous two days: “00” (neither was an STD), “01” (two days ago was not but yesterday was), “10” (two days ago was but yesterday was not), and “11” (both yesterday and the day before that were STDs). This means there are four (time-of-year dependent) transition probabilities: 

These probabilities certainly exist, whether the process follows a 2nd-order Markov Chain model or not! It’s worth taking note of the fact that if the process follows a 1st-order Markov Chain model, then the probability today is an STD doesn’t depend on the state two days ago. This would mean that the probabilities 

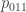
I took the NOAA-NWS data and used it to estimate all four transition probabilities. Here’s the result:

Not only are there differences between
It’s quite interesting (and counterintuitive) that early in the tornado season (during March),
Throughout the entire year,
When we used the 1st-order model, we got the following comparison between observed and expected numbers of long runs of consecutive STDs (expected in black, observed in red):

Using the 2nd-order Markov model, we get a result which is only slightly different, but does have more chance of very long runs:

The discrepancy between observed and modeled numbers is less. In particular, with this model the probability of 3 “runs of 12” in the 58-year NOAA-NWS record is about 1 out of 40, which is implausible but not unbelievable, so it’s significant evidence against the model but not very strong evidence.
And, there’s another factor which should also be considered. As Harold Brooks said in a comment,
There are a number of papers in both the formal and informal literature that changes in damage assessment over the years have led to a decrease in the reported intensity of the strongest tornadoes over the years.
Therefore it’s possible that the trio of runs-of-12 is in part due to the greater likelihood of earlier-in-the-record tornados being classified as F2 or stronger. After all, all three runs-of-12 are from 1967 or before. If tornados were ranked in those earlier records as they are today, we may not have seen so many long runs.



Could you do a markov chain analysis of the first half of the dataset, and of the second half – if there is a change in reporting, might it show up in such an analysis? (probably not enough data to do this well, but a boy can hope)
I had wanted to do a 2nd-order, but messed up the transition probabilities somehow. p011>p111 in March is not counterintuitive to me. It’s a reflection of large-scale weather systems moving across the country. It typically takes a couple of days for systems to go from just east of the Rockies to the East Coast. Typically (go back to 14-16 April, 25-27 April, noting that systems start to move a little more slowly as we move out of winter), you can see reports move east. I think the p111 problem is that many times the large-scale system will have moved off the coast by the time you get to the third day.
If you want to do the different periods, the first big break in practices is ~1975 (it took a few years to implement and the presence of 3 April 1974 makes it hard to see when it starts). The second is ~2001. 1975-1999 is a relatively homogeneous rating process. It’s also possible that using F1 and greater may be a better choice for longer consistency. In a crude sense, if the early tornadoes were detected they were almost certainly at least F1, but they were overrated by ~half an F-scale. In the last decade, the community has been much more conservative about rating tornadoes. That’s a big part of the absence of F5 tornadoes and dearth of F4 tornadoes from 2000-2007.
I was going to make the same comment as Harold regarding the intuitiveness of higher p011 in early spring, but then I noticed that p111 was higher than p011 in December and January and realized I don’t understand after all.
[Response: I left out the error bars because it made the graph cluttered — but they’re larger for p011 and p111 in Dec/Jan simply because there are fewer tornados, so fewer samples on which to base the estimates. The differences aren’t significant for those months.]
Thank you for the link to Brooks et al 2003, an outstanding work I believe the few storm chasers here have already read. do I read it correclty enough to say (informally) the potential for tornados in US midwest is at least 3 times that of anywhere in Europe, and for the most of Europe more than 10 times that?
I found the comment which John N-G commented on at his blog rather disconcerting. (No offense to John or Harold here).
When I read Harold’s comment, I found it interesting but not being familiar with him, I googled. It was quite clear that he is an incredibly good source. No need to know which side of the political fence he sits on. Thanks for the comment Harold. Is there any work being done to try and homogenize the record? It seems like an interesting problem.
Homogenizing the record is really hard. Grazulis’s work on significant tornadoes (F2 and greater) is one effort that’s pretty good. It’s clear that there’s a break in it about 1921 in terms of occurrence. One of the main points of the environments work is to use the relative consistency of the environmental observations over the years as a proxy for occurrence. Build relationships between signficant (5 cm hail, 65 kt thunderstorm winds, F2 tornadoes) events and environments when the event observations are good and then use the environments as estimates. There’s some work on satellite estimates of hail that qualitatively looks like the environment obs estimates. I’m optimistic we can use the so-called 20th Century Reanalysis, which uses surface pressure data and sea surface temperatures with an ensemble Kalman filter to estimate the 4D structure of the atmosphere, to get qualitative descriptions of storm days. There are some quantitative issues (moisture may be a little low), but most of the old events I’ve glanced at (1884 Enigma Outbreak, 1890 Louisville, 1896 St. Louis, 1905 Snyder OK, 1925 Tri-state, and even overseas events, e.g., 1934 Finland, 1875 Austria) look good pattern-wise. If we can figure out a good way to quantify the patterns, we can go with a lot from that. I’ll be advertising for a post-doc in a few weeks to look at that and other issues.
PBS features an interview with Brooks.
h/t Capital Climate.