
Bayesian statistics offers rich rewards, including that it gives you a probability distribution for everything. But there’s always the pesky question of how to define what’s called the prior probability distribution, especially when we don’t have much information to go on. In such cases, we usually try to define a “non-informative” (or maybe “non-informed”) prior, i.e., one which doesn’t make any assumptions, and has the smallest possible impact on the final answer so we can let the data speak for themselves.
Suppose for instance we’re flipping a coin to estimate the probability of getting “heads.” We can call this probability 


We start with the distribution for the outcome if we already know the parameter

This is called the likelihood function.
Now we must combine the likelihood function with some prior probability distribution for the parameter 
Specifically, the posterior probability distribution for the parameter 


We can determine the constant of proportionality using the fact that the posterior distribution, like all probability distributions, must give a total probability of 1.
For the coin flip we certainly know the likelihood function. But what prior distribution should we use – especially if we have no information to go on? A common choice is the uniform prior, for which the prior probability is constant

so the posterior probability is proportional to (i.e. equal to some constant

We determine
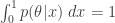
which gives the final form of the posterior distribution as
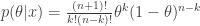
What Bayes’ theorem has given us is not an estimate of 
But the uniform prior isn’t the only choice. There are good reasons to use what’s called a Jeffreys prior, which can be justified by minimizing a certain measure of the probable “discrepancy” between the model and reality. For the coin flip the Jeffreys prior is
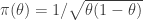
and the posterior probability distribution turns out to be

where 
Using the Jeffreys prior, the mean of the distribution is now 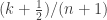
In fact if we have enough data (i.e., if both 
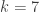

By the time we get to 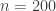


As is generally the case when the number of data grows, the results using different priors will converge to each other.
But in some cases we don’t have enough data. We may actually have plenty, we might have done 200 flips, but we don’t have enough “heads” to make 

Computing their respective means emphasizes how different the results are. The Jeffreys prior gives a mean value of 

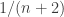
There are very good reasons to use the Jeffreys prior, it’s based on sound theoretical principles. But in this last case, when the difference between the use of two plausible priors is so large, we need to be aware that the result may be overly sensitive to the prior. That calls for some extra caution. Perhaps it’s ill-advised to put too much faith in either choice — we have to recognize that uncertainty in our prior distribution is a big factor in the uncertainty of the final answer.
In fact I’d like to propose an aphorism. I forget who it was who said something like, I wouldn’t want to ride on an airplane whose safety depended on using the Lebesgue integral rather than the Riemann integral (referring to two different definitions of the integral, both of which serve perfectly well for practical problems). I’ll paraphrase that with my aphorism: I wouldn’t want to ride on an airplane whose safety depended on using the Jeffreys prior rather than a uniform prior.



Nice introduction to Bayesian ideas, “we have to recognize that uncertainty in our prior distribution is a big factor in the uncertainty of the final answer” is a certainly a useful take home message. It could be argued that the Jeffreys prior is not as “un-informed” as the flat prior as it is justified by the prior knowledge that our prior knowledge should be invariant to re-parameterisation, so the reason it gives different results is because it reflects a different state of prior knowledge about the problem. A nice thing about the Bayesian approach is that it encourages discussion of our assumptions (i.e. the prior) – the conclusion of even a correctly constructed logical argument is only as valid as its premises.
Tamino,
Interested to know what you think of model averaging, as proposed by Burnham and Anderson. Might the average over priors give a better result when the results are divergent?
Shouldn’t final Jeffries mean be 1/(2n+2) ?
[Response: Doh! Yes.]
Wasn’t there this thing that the Jeffreys prior was ‘invariant’?
I remember it was discussed in Jaynes. Unfortunately I found that a little too theoretical to appreciate. I understand that, e.g., the uniform prior is invariant under linear transformation. But what is the thing with Jeffreys?
Nice discussion Tamino. I have always found it very intuitively appealing (read a really neat trick!) that, taking advantage of the fact that the Beta distribution is a conjugate prior for the binomial likelihood, and that Beta(1,1) ≡ Unif(0,1), and finally that the Beta distribution is so flexible for any continuous random variable defined on the unit interval [including the Jeffreys prior ≡ Beta(½ , ½) ], that you can express the mean of the posterior distribution, which itself is another Beta, as a weighted average.
Using a slight re-parametrization of α and β in Beta(α , β) to Beta(μ , M), where μ = α / (α + β) is the prior mean and M = α + β, is a measure of the prior precision, we have
Posterior Mean = M/(M+n) * μ + n/(M+n) * (k/n),
Which is to say it’s the weighted average of the prior mean and the MLE, and the weighting reflects in a very reassuring way the relative information in our prior and our sample. [For both α > 1 and β > 1, the beta prior distribution is concave downward and increasingly concentrated around its mean as the sum α + β increases.] Truth-in-commenting disclosure: I owe all this fun stuff to Brad Carlin and Tom Louis’ fine Bayesian stats book.
since the posterior distributions are not symmetric, wouldn’t the posterior median be a better point estimate than the posterior mean? Are the posterior medians very different for the uniform and Jeffreys prior?
[Response: The posterior median is an excellent point estimator, and it’s also invariant under transformations of the variable . I don’t know for sure, but I suspect the uniform and Jeffreys posterior medians are in about the same 2:1 ratio as the means.]
. I don’t know for sure, but I suspect the uniform and Jeffreys posterior medians are in about the same 2:1 ratio as the means.]
I’m rather surprised you don’t mention the use of uniform /Jeffries prior in estimates of climate senstitivity – JA has been baning on about this for years.
[Response: And I think he has a good point.]
The problem with JA’s argument about bounding climate sensitivity is that even with a Cauchy prior, the result depends critically on the location of the prior. I agree it would be nice to bound climate sensitivity a whole helluva lot better, but I get nervous when my prior dominates the analysis.
Only slghtly off-topic:
Pisarenko & Rodkin
Heavy-Tailed Distributions in Disaster Analysis
Springer, 2010.
Emphasis on earthquakes, but considers other distributions of extreme eventss as well.
O/T – Tamino, are you still panning to do a second installment of this…?