
Suppose you’re an astronomer interested in variable stars — stars which change brightness. You decide to collect some data on the brightness of a newly discovered variable. It never gets brighter than magnitude 9, which is too faint to be detected with the naked eye, but you’re at a major observatory so that’s no problem. You have access to, and training in the use of, high-precision CCD photometry so your data will be outstanding. Of course, you can only see it at night and there’s stiff competition for observing time on the observatory telescope, but you manage to schedule regular observations at precisely midnight every 16 days for slightly over a year.
If we graph the data and examine the graph, we might instantly know that we understand its behavior:

Such a graph is called a light curve. By the way, magnitude is an “inverted” scale, for which higher numbers indicate lower brightness, so the numbers on the magnitude axis go from highest at the bottom to lowest on the top. Pretty clearly, the star fluctuates in periodic fashion, repeating the same cycle over and over again (at least, it did while we were watching it). The period is about 80 days according to the graph, which is confirmed by Fourier analysis of the data, showing a strong peak at frequency 0.0125 cycles/day, period 80 days.

Well … there it is. Case solved.
You’re preparing your analysis to be published in the Information Bulletin on Variable Stars when you find, to your dismay, that another observer has beat you to the punch. Not only that, they collected much more data than you did, observing the star at exactly midnight every day. Woe is you! If only you had published faster! But when you look at their light curve, suddenly you’re glad you didn’t publish faster:

Their graph indicates that the period is only 20 days. So does their Fourier spectrum, indicating frequency 0.05 cycle/day (period 20 days):

What the … ???
You go back to your original data and re-compute the Fourier spectrum, but this time, instead of accepting the default settings you instruct it to scan a larger frequency range — one which will include the frequency reported by your competition. In fact you scan a much larger frequency range. You get this:

Sure enough, there’s the peak at frequency 0.05 (period 20), and there’s your original peak at frequency 0.0125 (period 80). There are also peaks at frequencies 0.075, 0.1125, 0.1375, and 0.175 (periods 13.333, 8.889, 7.273, and 5.714). And they’re all the same strength. According to this, the “true” frequency (if there is such a thing) could be any of those values.
In fact the power spectrum looks like a sequence of identical copies of the power spectrum from frequency 0 to 0.03125, laid end-to-end, with odd-numbered copies in normal order and even-numbered copies in reverse order. You email the other observatory and request their data, which they kindly provide, then you Fourier-analyze that with a larger frequency range:

There’s the peak at frequency 0.05 (period 20), but none at 0.0125 (period 80) or those other periods you noticed. But now there are peaks at frequencies 0.95, 1.05, and 1.95 (periods 1.0526, 0.9524, and 0.5128). Could one of those be the “real” frequency? And … what the heck is going on here anyway?
You decide to superimpose your data (plotted in black) with theirs (plotted in red)

Aha! What you’ve observed is the phenomenon called aliasing. They believed the star is fluctuating with frequency 0.05 cycles/day, you believed in fluctuation frequency 0.0125 cycles/day. It turns out that at the times you chose for observation, those two models have exactly the same values — each is an alias of the other. It’s rather like you were looking at the behavior through a “picket fence” of time. The two different fluctuations are quite different when you weren’t looking, but they’re identical when you were.
It arises because you have observed the star at perfectly regular intervals of 16 days — or to put it another way, your data show a sampling frequency of 1/16th observation per day, or 0.0625/day. Suppose the true frequency is f so the light curve is given by
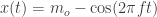
The quantity 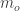

Then the data values are
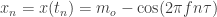
Now consider a different fluctuation at frequency 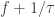


But it’s a fundamental property of the cosine function that it is periodic with period 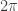
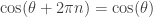
for any number 
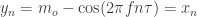
i.e., they’re exactly equal to the old values. If the data are only observed at regular intervals, then there’s simply no way to tell the difference between fluctuation at frequency f and that at frequency 
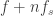
Now word arrives that yet a third astronomer at a third observatory has analyzed the spectrum of the star — not the Fourier spectrum, but the optical spectrum (breaking light into its component colors). On that basis, they suggest that the star might be a Cepheid-type variable. Cepheids can have periods as long as 20 days, but they can also have periods as short as a day. Now there’s genuine ambiguity about the period of this star. The once-a-day data indicate the period might be 20 days, or 1.0526, 0.9524, or 0.5128 days. Which is it really?
Fortunately, this star wasn’t just observed by professional astronomers with major observatory telescopes. It was also observed by a host of amateurs, some using small telescopes, some just binoculars. They didn’t apply high-precision CCD photometry, they used visual photometry, comparing the star to nearby stars of known magnitude for a visual estimate of its brightness. Visual data aren’t nearly as precise as CCD photometry. But there’s an army of amateurs worldwide, and they’ve collected a lot more data than the pros. And … more to the point … their observations are not taken at regular time intervals, the amateur data shows uneven sampling. Here’s their data:

It doesn’t look like much — and it’s certainly very noisy. But when we Fourier analyze the data we get this:

It turns out the true frequency is 0.95 cycles/day, and the true period is 1.0526 days.
In the real world, professional astronomers are well aware of the phenomenon of aliasing, they tend not to observe at exactly the same time of night every time, and they rarely take only one observation per night anyway. So, this is just a hypothetical example. But it illustrates the phenomenon of aliasing quite well.
When data are sampled at a regular sampling frequency
Even with uneven sampling we can still have aliasing, if the density of data is periodic. The aliases generally won’t be exact copies of the real signal frequency, only approximately so, and alias peaks in a Fourier spectrum will generally be weaker than the real peak. But if the data density is very strongly periodic, the aliases can be nearly as strong as the real signal, sometimes so much so that it’s not possible to be sure which is real. And unfortunately, some periodicity in data density is unavoidable. You can’t observe most astronomical objects during daytime, so there’s a natural sampling frequency of once per day. Every year the sun travels through the constellations of the zodiac and often obscures our targets, so there’s another natural sampling frequency of once per year. Each of these cycles leads to aliasing in period analysis, but if the observation times are reasonably irregular then the aliasing is usually quite manageable.
Uneven sampling is a solution to the aliasing problem, but it has problems of its own. It alters the behavior of period analysis like Fourier analysis, making it — and its statistical evaluation — more complicated. But much mathematical ingenuity has developed solutions to many, even most, of those problems, so on the whole, in my opinion, uneven time sampling is not the bane it was once thought to be, it’s a great blessing.
It’s also true in the real world that telescope time at major observatories is very hard to come by. And there really is an army of amateur astronomers worldwide who contribute vast amounts of data to our scientific knowledge. Some of them have even mastered the art of high-precision CCD photometry (with the help of not-too-expensive CCD cameras). They are an extraordinarily valuable resource to the astronomical community and have contributed mightily to our understanding of the universe. In fact, some of the most famous astronomers in history had their start as amateur observers. But that is another story …



Readers of this post might want to read up on the debate about the period of the time delay in the double quasar 0957+561 (the first gravitational-lens system discovered). As Sjur Refsdal pointed out back in the 60s, all observational quantities except one are dimensionless. The one with dimension has the dimension of time, and is the delay between the images. (Two images of the same source, but one has a longer path length.) Thus, with a model (mass distribution) of the lensing galaxy, measuring the time delay gives the distance to an object at a cosmological distance, something difficult to do otherwise. (The usual method is a distance ladder, with errors creeping in at every rung.) One group, led by Bill Press, claimed a long time delay (and hence greater distance and lower value of the Hubble constant), while another group containing Refsdal in Hamburg and Jaan Pelt from Estonia favoured a smaller value for the time delay. Eventually, better observations showed that the short value was correct. The main source of the ambiguity was how to take irregularly spaced observations into account (in this case, observations couldn’t be made when the Moon was too bright, and except in the far north the system isn’t visible during the entire year). Pelt had expertise in this area, some of it in collaboration with variable-star observers in Finland, who could observe during the dark winter without the Sun messing things up.
http://en.wikipedia.org/wiki/Sjur_Refsdal
http://www.aai.ee/~pelt/curri.htm
Wonderful explanation, terrific punchline w/the amateur observers. Thanks!
I apologize in advance for being extremely off topic, but what can you say to those attacks you and Dana1981 received here:
[Response: All the response Tisdale deserves.]
I see a bunch of lines heading in the wrong direction, upward, no matter who is explaining the matter. Tisdale has in his own elliptical way helped confirm that the ocean is warming up. I’m left wondering what is the point of the whole affair; we already knew the ocean is warming before Tisdale presented his reanalysis.
Leaving aside the convoluted (and distractingly snarky) narrative, Tisdale’s intended message seems to be that we’re to seize on fine-tuning of the OHC slope while ignoring the blaring message behind any given version.
I would agree – a great deal of “Look at the tree!” while ignoring the forest.
Will you ake a post defending yourself and Dana1981?
His arguments are strong because of the use of graphics. For me is difficult to challenge them despite having all the info I could get about global warming for many years (at least since 2006).
I suspect that other people wil found Tisdale arguments reasonable, so it will be great if you clarify this thing.
I went a few rounds with Tisdale on this topic (an earlier post of his) and likewise found it difficult to rebut him.
Hansen’s model/obs comparison began with the first year, 1993, being the intersect for model and obs. Tisdale made his first year, 2003, the intersect, but 2003 is a high anomaly, so the model will likely run too high for a decent comparison. But Bob replied that Hansen’s choice was simply fortuitous – indeed, I could find no rationale for ‘baselining’ the OHC model and obs amongst a couple of very long papers authored by Hansen and others that referred to this comparison. I could not thus argue the superiority of Hansen’s intersect at 1993. IIRC, 1993 appeared to be a slightly low anomaly in the data, so the argument against Tisdale’s 2003 intersect seemed to apply (to the reverse effect) re Hansen’s model obs comparison.
I ended up thinking that unless Hansen’s intersect (or ‘baseline’?) could be validated as more than a fortuitous start point for the model/obs comparison, Tisdale sort of had a point. I wasn’t at all convinced that his question “when will the models be falsified” was valid, but I did question the validity of Hansen’s model/obs comparison.
I’m not convinced that Tisdale need focus on the intercept or starting point, the impression I garnered from his recent post at WUWT (or his site, whichever) is that the trend of 0-700m OHC data and the model output (which I think can be reasonably represented by a straight-line continuation of the 1993-2003 trend, I posted a bit on this at our SkS post and my comments are, as of typing this, still the last on the page).
The data he’s using for OHC is from the UKMO EN3 analysis, which seems to have been performed in 2005 or 6. I’m looking through Levitus’ 2012 work today to see if they at all discuss discrepancies between the more pronounced warming in NODC and the UKMO OHC data, but either way the use of the UMO data is at least convenient for showing a too-aggressive model.
Even such, that’s not the real issue, and as right as Tisdale might be about how the model runs project away from the observations, they’re modeling based on the SRES. The smoothness of the future projections from 2004 makes me think that the SRES specifications are simply too simplistic and don’t accurately represent the forcing we have really observed over the past decade. The aerosol loading and prolonged minimum, I would bet, weren’t predicted by A1B for instance, which in all likelihood is the scenario Tisdale is using to say “look, the straight-line projection isn’t a bad estimate of what the model says.” Which just misses the whole point about it not being a hind cast anyways.
(BTW, the RC posts on this appear to use a 1975-1989 baseline, and the model seems to do well in hind casting, so…? Where’s the 1993 issue coming from?)
Sorry, got lost in parentheses. That the trends are different, is what I meant to say in the first paragraph. The UKMO OHC trend is relatively flat, whereas the model projection is not.
Alex,
“BTW, the RC posts on this appear to use a 1975-1989 baseline, and the model seems to do well in hind casting, so…? Where’s the 1993 issue coming from?”
Tisdale’s OHC thesis has been based Hansen et 2005. The OHC model/obs comparison in that paper starts at 1993 –> 2003. Tisdale reiterates this basis in the latest post linked above. Tamino posted on that a while back, pointing out that Tisdale shifted the modeled slope upwards (intercepting with the high anomaly of 2003), failing to extend the model directly from Hansen et al 2005. Tisdale’s reply, which I found hard to rebut, was that there was no stated rationale for Hansen’s choice (intercepting model and obs at 1993), and that the agreement betwen model and obs may have been simply fortuitous. When I looked at various OHC data, it appeared that 1993 was a slightly low anomaly in the OHC record, and that Hansen’s unexplained choice for baselining that comparison may indeed have been fortuitous. Bob’s main point was that he had made the same choices as Hansen, just started the comarison at a different year, and that there was no requirement to extend the model slope from Hansen et al because the baselining for it had not been rationalised in any way (that I could discover).
I left that conversation unconvinced by Tisdale’s model/obs comparison, but also dubious about the legitimacy of the Hansen et al 05 model obs comparison. Tisdale is making hay out of the corrections at RC, which, superficially anyway, favour his earlier objections. Though I tried to investigate this earlier, ultimatley I’m not savvy enough to determine either way. I’m in the same boat as ‘From Peru’.
It is also worth pointing out that there are armies of amateur weather frogs out there taking data. Some people have too much time on their hands:)
More seriously, amateurs are great strengths of astronomy, botany and other fields
Note: with “strong” and “reasonable” I do not mean that they really are good arguments, but just that they have the appearance of being that for common people like me that know little of the details of statistics and climate modelling.
Excellent post thanks.
Hi Tamino. I’m writing about your data analysis service. I know you think my idea that ozone is killing trees is a bunch of shit, but it’s not.
[Response: It’s not that. In fact I haven’t seen the data for ground-level ozone, or tree mortality (and its potential causes) to know. What I want to avoid is threads on this blog being derailed into discussion of that topic.]
You should check out my blogpost from today for the most recent corroboration, http://witsendnj.blogspot.com/2012/05/vertigo.html or if you have more time and want links to research, a book which can be downloaded as a pdf for free at the bottom of this link: http://www.deadtrees-dyingforests.com/pillage-plunder-pollute-llc/
But that’s not why I’m writing. If I’m correct, in addition to a sudden acceleration in the rate of CO2 rise (because trees and other plants are dying and not photosynthesizing) there should be a narrowing of the seasonal difference in the CO2 increase. In other words, if the main CO2 sink from vegetation is in the northern hemisphere, because that is where the most land mass is on earth, then rising line in the graph goes up and down every year based on the seasons in the northern half of the globe.
If it’s true that trees and other plants are behind the sudden increase in overall CO2, or will be in the future, that differential variability should be decreasing. I think?
I hope I’m explaining this right, and I wouldn’t have a clue how to find out. I wrote to Ralph Keeling at Mauna Loa and he wrote back: This would indeed be a good topic to flesh out further on our web site. At Mauna Loa, the amplitude of the annual cycle has increased by 15 to 20% since measurements began in 1958. I attach a now “classic” paper on this subject written by my father and colleagues in 1995. If anything, there has been relatively little change in the amplitude since 1995. Sites further north, appear to show larger increases overall. The changes are not fully understood, but the mechanism that my father proposes involving the lengthening of the growing season, is clearly part of the story.
So if you know of a way to measure any trend, I would love to know about it. I can afford to treat you to probably just about a draft beer, or maybe two, for the information.
thanks,
[edit]
[Response: The “data analysis” link is for my business — that’s what I do. As much as I’d like to help people with data analysis, it’s a simple fact that folks won’t pay for what you regularly give away for free.
However, the annual cycle in CO2 is on topic for this blog, so I guess I’ll take a look.]
Is it better to use random uneven sampling or stratified uneven sampling? If the latter isn’t something I just made up, I imagine you’d need to have some well-defined hypotheses to design good stratified uneven sampling. How important is it to have an idea of what the competing models (periodicity) are for the purposes of doing random uneven sampling?
[Response: I’m not sure what “stratified uneven sampling” is. But I’m convinced that truly random sampling is a big advantage. You don’t need to know the periodicity in order to take advantage of it. I’ve seen cases in which periods which are much shorter than the smallest interval between observations can be identified unambiguously with uneven sampling.]
Okay, let me try again. What I’m taking away from this is, for example, if you have a one year study and enough funding for 52 one hour observations, DO NOT schedule your samples with regular periodicity (like every Saturday at midnight). I’m worried, though, that temporally random sampling could miss some periods of interest, or most samples may be in just a few months. The problem is most accute when the number of observations is quite constrained like this. An example of what I called “stratified uneven sampling” would just be to allow random observations, but constrained to a minimum of 3 or 4 samples per month.
I bet if my statistics vocabulary was better developed, I could have asked this question with less confusion. It may be an important question that people study all the time. In my field, samples are always limited by funding, and I’m wondering if there are general algorithms to help folks find sampling strategies more efficient than purely random sampling.
[Response: Maybe there are, but I’m not aware of them. I would say this (just of the top of my head): for finding truly periodic behavior, a genuinely random sample is probably best. But if other behavior is expected (e.g. “outbursts” as are exhibited by many variable stars), then the stratified random sample might be better. It would be sufficiently random to avoid aliasing, and sufficient regular not to miss outbursts (as long as the maximum time between observations was less than the duration of an outburst). Perhaps best would be to randomize the time difference between observations according to a uniform distribution with some maximum value?]
Well, the catch with designing a stratified sampling protocol is that you need to know something about the phenomenon first, so that you can decide how to “appropriately” stratify it.
The flip side is the approach I’ve often seen, which is to abandon any previous knowledge of the system and start every sample and study as if you’re totally ignorant again… Doesn’t float my boat, but some people seem to make successful careers of it.
Steve, Bob pretty much nails it. When we perform a Fourier or wavelet analysis, we know little to nothing about it. These are really just sophisticated techniques of exploratory data analysis (EDA). All they can do is reflect the data, but the data reflect both the phenomenon and the sampling protocol. It is pretty much the same reason why random sampling is needed in quality assurance. Now the trick is “define random”.
thanks Tamino, Bob, and Ray for the responses!
I believe that the first time someone claimed to have found a planet orbiting a pulsar it was found to be an artefact due to aliasing. The incredible thing is that everyone was very shocked by the idea of a planet orbiting a pulsar, existing theories had a really hard time accounting for that, and they were terribly relieved when it was found to be spurious. Then, just one year later, an incontrovertible example was found.
Anyway I’m a professional astronomer and one of the things I think is really awesome about astronomy is how much amateurs contribute to the field. And it’s not just an helpful bonus or a useful additional source of information – their work is vital and some fields of astronomy would simply not be possible without it. I study supernovae and novae, and without the work of amateurs across the world who discover these objects and monitor them, it would be impossible to understand these objects. There are not many fields of science where amateurs can even contribute, let alone be essential.
Tamino, a very nicely written post (as usual), I’m sure to direct my students to it in the future. Incidentally, I’m involved in making astronomical observations from Antarctica, where one of the big advantages is the lack of 24-hour aliasing from the sun rising/setting. And back in the 1970’s as a high school student I used to make visual observations of variable stars for Dr Frank Bateson’s Variable Star Section of the RASNZ. Lots of fun!
That’s all well and good, but when you’re taking temperature trends, cherrypicketing can actually be helpful.
Besides, aliasing has been good to Horatio (no threats, etc)
Tamino,
Are you familiar with with what astronomer Rick White calls “Golden Sampling” ?.
A lot of the stuff one reads related to the golden ratio seems to be quite “mystical” but White’s proposed use of Fibonacci numbers and the golden ratio (for sampling and telescopes) seems quite down to earth (so to speak) — IHHO (don’t know much about this stuff)
That’s a video I’m going to watch a second time. An excellent complement to Tamino’s post (and his second answer to my query is compared to Fibonacci sampling from approximately 23-26 minutes). His method of distributing samples on a circle and then projecting down onto a line seems to bias sampling toward the beginning and end of a time series and samples the center less. That could very well be the right thing to do (since some information regarding the middle is provided the samples before and after), but I also think it’s an added wrinkle/implication to his approach that I wish he addressed.