
As some of you know, I devised a method for aligning temperature data records which I believe is better than the “reference station method” used by NASA GISS. However, the difference is small and it doesn’t change the overall global result when small regions are averaged, then those regional results are area-weight-averaged to produce a global estimate. It’s an interesting, and possibly useful, refinement which doesn’t change the overall final answer.
In any case, the method computes an offset for each station which will bring it into alignment with the other stations, based on the idea that the difference between station data sets which are at nearby locations is approximately constant. RomanM modified my method by computing a separate offset for each station for each month. This compensates for possible differences in the annual cycle of different nearby stations. If your purpose is to study the annual cycle then this is a loss of information, but if your purpose is to study anomaly (the departure from the annual cycle) this is a gain. Most of the time we really want to get at the anomalies, so on the whole I’d say his method is better.
But nowadays I use yet another method. It’s based on the Berkeley method for combining station data to form a global average. They use a “weighting function” to represent the area over which a station should be considered to have an influence. The temperature estimate for a specific location is the weighted average of nearby stations, with closer stations given greater weight by the weighting function. I ignored the weighting function altogether so that all stations in a given region can be equally weighted to compute a regional average. My modification is therefore specifically tailored to produce a local estimate, whereas the Berkeley method is designed to include everything in one fell swoop and produce a global estimate.
Anyway, here are the details.
We have a number of station data records 

We assume that there’s an offset 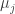

We also assume that there’s a single regional average temperature 
![Q = \sum_{times~k} \sum_{stations~j} \Bigl [ (y_j(t_k) - \mu_j) - \gamma_k \Bigr ]^2](https://s0.wp.com/latex.php?latex=Q+%3D+%5Csum_%7Btimes%7Ek%7D+%5Csum_%7Bstations%7Ej%7D+%5CBigl+%5B+%28y_j%28t_k%29+-+%5Cmu_j%29+-+%5Cgamma_k+%5CBigr+%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002)
Defining equations for the offsets 
![\partial Q / \partial \gamma_k = -2 \sum_{stations~j} \gamma_k \Bigl [ (y_j(t_k) - \mu_j) - \gamma_k \Bigr ] = 0](https://s0.wp.com/latex.php?latex=%5Cpartial+Q+%2F+%5Cpartial+%5Cgamma_k+%3D+-2+%5Csum_%7Bstations%7Ej%7D+%5Cgamma_k+%5CBigl+%5B+%28y_j%28t_k%29+-+%5Cmu_j%29+-+%5Cgamma_k+%5CBigr+%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002)
and
![\partial Q / \partial \mu_j = - 2 \sum_{times~k} \mu_j \Bigl [ (y_j(t_k) - \mu_j) - \gamma_k \Bigr ] = 0](https://s0.wp.com/latex.php?latex=%5Cpartial+Q+%2F+%5Cpartial+%5Cmu_j+%3D+-+2+%5Csum_%7Btimes%7Ek%7D+%5Cmu_j+%5CBigl+%5B+%28y_j%28t_k%29+-+%5Cmu_j%29+-+%5Cgamma_k+%5CBigr+%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002)
We can rearrange these two equations. The 1st says that for any time

where 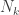

where 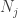
This system of equations is actually underdetermined. If I add a constant c to all the station offsets 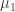
To compute the values, I begin by setting all station offsets to zero. Then I use equation (1) to compute the average temperature 
These values are only approximate, so I repeat that procedure, at each step computing new estimates of offsets
About the code:
It’s an R function. Its inputs are a set of times t, a set of temperatures x, and a set of station identifiers part. It returns a list with two elements, the computed average temperatures and the station offsets.
The first entry in the list is actually a data frame with 5 columns. Column 1 is the time, column 2 is the average temperature for that time, column 3 is the number of stations with data for that time, column 4 is the standard error of the average, column 5 is the standard deviation of the offset temperatures. The second entry is simply a vector of the station offsets, and the 1st element of this vector will be zero.
There are a few other options. You may want the data frame to include the raw input data, in which case you can include the option “full=T” and the data frame will have more than 5 columns, it will also include a column for each raw input data set.
You can also set your own threshold for when the calculation is considered to have converged. By default, if the sum of absolute values of the changes in station offsets is less than 0.001, it is considered to have converged. If you want to insist it must be less than 0.000001, include the option “offres=.000001”.
For data to be combined at a particular time, the time values must match exactly. However, if you want to round off the times to a particular number of significant digits after the decimal point before insisting that they match, say rounding times to 3 decimal digits before computing, include the option “tround=3”.
By default the average temperatures will be rounded to 4 digits after the decimal point. If you want 6 digits instead, include the option “xround=6”.
To get the code itself, download this pdf file, then copy-and-paste it into a text editor and save that as an R function.
There’s always the possibility that I’ve made an error, or that my code is fine but my description is faulty.
And it almost certainly could be optimized — perhaps someone can modify it so that it’s more efficient either in the time of computation or in the memory required. Feel free.



Hey Tamino,
Interesting post and interesting approach. Do you by any chance have a script for the downloading of the data and putting into the formatting this method requires. Something like that would be really useful, particularly if there was a way to specify via lat/longs. I.e. to cover regions such as the arctic for example.
[Response: No, but maybe Mosher’s programs will do some of that for you.]
Is there any particular reason to conclude that it would be wise to choose one threshold over another with respect to the absolute value of the sum of the offsets. For a publication to be submitting very soon we used this approach you outlined for a study region and found it hard to rationalize why we chose 0.0001 as our value for the sum of the offsets. I guess I should mention that it was your previous posts on the subject that led us to eventually use the adapted method we did so a little bit of a thanks to you is in order.
I should note that ours was done by manually downloading the information from gchn and environment Canada and manually doing this process in excel. It is therefore great that the R code is available and hopefully I can figure out how to use it.
[Response: There probably is a rational choice, but honestly I just pulled it out of my ***. It seems to work fine, and I expect the net error will be bounded by the threshold. In fact that’s probably not too hard to show.]
Some time ago, I whipped up a program that implements a *very crude* global-average anomaly gridding/averaging procedure.
I simply averaged all data from all stations sharing the 5-digit WMO “base” identification number to generate a single temperature time-series per 5-digit WMO base ID.
Then I computed the 1951-1980 baseline temps for each 5-digit WMO ID for each month. Threw out all station/month data for all temperature time-series for which there weren’t at least 15 out of 30 years of good data for each station/month (results were very insensitive to this number, btw).
Computed station anomalies per the above baseline values, ran it all through a very simple gridding/averaging routine (20deg x 20deg lat/long grids at the equator, crudely adjusted to give approximately equal grid areas as you go N/S).
Very crude, very amateurish, I’ll freely admit — something that high-school AP students could do.
The results? GHCN monthly-mean raw data run though this program generated results that matched NASA’s official “Meteorological Stations” pretty decently. Results here: http://img541.imageshack.us/img541/9994/landstationindexnosmoot.jpg
No offset-alignments or anything fancy like that — just simple, dumb anomaly gridding/averaging of raw GHCN temperature data.
Nothing new or exciting here — Tamino could do this in his sleep after pounding down a fifth of Jack Daniel’s (and chased by a couple of pints of pale ale).
But what this does show is how robust the global-warming temperature signal is; no matter how crudely you process the surface temperature data, you will get results not only in NASA’s ballpark, but pretty darned close to home plate — unless you completely f*@! it up, that is.
Kinda puts some perspective on all the *years* that deniers have been attacking the NASA/GISS global-temperature results, without doing so much of a lick of high-school-quality analysis of their own.
That should be “Meteorological Stations” *temperature index*….
I mentioned this in another thread, but it seems to me the “Berkeley Method” of treating each station discontinuity as the beginning/end of a unique series would be ideal for analyzing the radiosonde data, which is replete with problems due to the introduction of different measuring equipment.
Tamino Had you ever considered using something like a Barnes(1964,1973,.1994) objective analysis to provide an area averaged value for the temperatures. A Barnes objective analysis is commonly used to determine the “correct” value for an area given a number of samples. The basis for the analysis is a Fourier series fit to the data.
Nice post Tamino. I was fooling around with a similar method not too long ago. I modeled each station as T(i,t) = T(t) + k_i*dz_i + e, where T(t) is the grid point temperature, T(i,t) is the ith station value, k_i is the lapse rate at the ith station and dz_i is the difference in altitude between a reference station and the ith station. I estimate the lapse rate using each station as a reference, so for N stations, I have N estimates of the lapse rate for the ith station. Then I adjust each station’s temperature by its mean local lapse rate to bring it up or down to the elevation of the desired grid point. This procedure is performed for all twelve months to allow for annual variation in the lapse rate. The purpose of this method is to create not just a grid of temperature anomalies, but a grid of temperature. I was also thinking about introducing kriging into the mix to avoid having to predefine a radius of influence for the weighting function, since that has been shown to have significant seasonal variability.
I’m taking a long weekend with the wife, so comment moderation will be slow and possibly nonexistent until Sunday night. Patience is a virtue.
“I devised a method for aligning temperature data records which I believe is better than the “reference station method” used by NASA GISS…..” – tamino
….THEREFORE ALL CLIMATE SCIENCE IS A FRAUD!! (hat tip Steve, Anthony et al.)
Tamino,
I wrote a program last year using a very similar least squares optimisation. It was also similar to the Berkeley idea, but I’ve used it for a lot of local temperature fittings, with anomalies. It uses density-based weightings, arguing essentially that the sums should really represent space integration formulae. I went on in V2 to represent the global temp by a spatial distribution rather than a single value.
There’s an overview of the early stages of the project here. Math description of V1 is linked here – this also links to the R codes.
The release note for the latest version is here. I’m now using a kind of Voronoi tesselation for the weighting. The Math basis for the spatial model is here.
I’ve completed a verification script for folks who want to play around with tamino’s algorithm.
I’ll do a posting of it along with instructions.
The verification consists of
1. A routine to create data to feed to his “align” function
2. His “align” function.
3. His function split into two smaller functions:
A. a function to create the big data.frame (zz)
B. the core math function ( which takes a data.frame as an input)
by splitting A and B, integration, testing and verification of
any attempts to speed up the code, (its already fast) will be
easier. ( we dont have to rebuild the data.frame every time)
I’ll be integrating the core math function in the Rghcnv3 package
over the next week. And then i’ll look at getting rid of the loops
in the code ( except the while loop) and see if that speeds things up.
Changes to the core math, of course, will be checked with the verification
script.
Great work tamino. Your code was clean and understandable and quick.
Now I get to give romanM and nick stokes some shit if their stuff is harder
to work with.
Here is the post.
I’ve split your code into two functions, the core math function should drop right into RghcnV3.
Package built and submitted to CRAN. usually takes 2-3 days to get all the binaries tested and posted, source should be up in 24 hours or less.
RghcnV3 version1.2 now supports your method for aligning stations and calculating a mean.
The function is called regionalAverage()
a demo of it is in the demo files demo(Texas)
the documents need more work, but its there for people to play with
Its so fast I have to go work on the other methods to speed them up.
Thanks!
[Response: I’m surprised it’s that fast.]
@Steven Mosher,
Would it be difficult to add bootstrapping, e.g. resampling of stations, to your package and obtain some information about the size of the confidence intervals? I guess fast methods will help to get a decent sample.
Tamino: yes it’s quick relative to all the crap I have to do for a common anomaly method:
1. compute the base period means
2. subtract
3. area average and weight ( weights change per month)
etc etc, plus all the checks along the way. When I get around to removing
your three loops it’ll be even faster. Getting the data in the right structure
( you use a matrix which is faster than data.frame) is half the battle. The next thing I will add for people is a method of selecting regions.. in due course
MP:
Bootstrapping should be easy.
I assume what you want is this.
You select a region. That region has say 50 stations. You want to
run tamino’s regionalizer on multiple random samples of that 50?
That’s a snap. I dont even have to add it to the package since you can do that in R easily. Just describe what you want done clearly. It’s fun for me and keeps me from saying stupid stuff on blogs.
@Steven Mosher,
Exactly yes, I noticed that Zeke had the same idea and posted some results. It would be a useful functionality in your package. I can imagine there are several possible sampling techniques. One catch with this method is that wit non uniform coverage the meaning of the confidence intervals is not unambiguous, but does give an impression.