
Suppose you are asked to determine how y, the severity of an unhealthy reaction to some toxin, relates to x, the amount of toxin one is exposed to. You expect ahead of time that the relationship will be monotonic, i.e. that increasing the exposure cannot decrease the severity, and that in fact the relationship will be “smooth” (whatever that means). You also have just enough laboratory resources to collect some actual data, so at equally spaced exposure levels from 1 to 9 you measure the reaction severity as accurately as you can, coming up with these data:

Suppose now that we want to know the likely severity at some point in between those integer-valued measurement points from 1 to 9? What if we wanted to know the severity for an exposure of 4.5, or 2.271? In other words, what if we want to interpolate to get an estimate?
The classic way would be to define a function at all values x from lowest to highest — not just the x values at which we have observations — by simply “connecting the dots” (as has already been done in the above graph). The line segments from one data point to the next define the function values at intermediate x values.
That’s fine, and the function so defined is at least continuous. But it’s not smooth, it makes instantaneous changes in direction at the observed x values (in other words, it’s derivative is undefined at the observed x values). In between those values, it’s perfectly smooth — a straight line segment is as smooth as can be — so this “classic” interpolation function is piecewise-smooth. But it isn’t smooth, and the merest glance at the jagged corners connecting the straight-line segments makes that obvious.
And we already said we expect y to be a smooth function of x. Perhaps we could find a smooth function which matches all the data values at the measured levels. It’s easy to do so: we can fit any 9 data points with an 8th-degree polynomial. Then we can hope that the polynomial approximates the smooth behavior we’re after, and compute the value of that polynomial at the “in-between” points in order to interpolate. The smooth function looks like this:

Ouch. That’s kinda wiggly and bumpy in ways that you don’t expect reality to be. First of all, we expected a monotone increase — up only — so that points with higher x can’t have lower y, but this “smooth” curve goes both up and down willy-nilly. Hell, it even dips to negative values, which for our “severity” variable is nonsense. And, it just keeps changing direction too fast and too often to be sufficiently “smooth” for us, it’s too “wiggly” and “bumpy”, too … “rough.”
Well, polynomials aren’t the only way to model a completely general function: we could use a Fourier series instead. We can model any nine data points with a 4th-order Fourier series, which gives us this:

Pfeh! That’s just as bad the polynomial fit!
What is Smooth?
Hold on for a moment here. We started out saying that polynomials (and the Fourier series) could give us a smooth function through our data — and they do. But then we say it’s not “smooth enough”? Just what does one mean by “smooth” anyway?
The strict mathematical definition of a smooth function is one which is infinitely differentiable. Polynomials meet that criterion, as do sines and cosines, so both polynomials and Fourier series do indeed provide us with smooth functions. But we didn’t like the fast wiggling, the jiggling around from point to point of our smooth functions either. What we really want is something that’s more smooth than just the fit-all-the-data-perfectly option.
It just so happens that most of the “rough stuff” is the fast stuff, and when it comes to Fourier analysis, the fast stuff is the high-frequency stuff. What if I fit a Fourier series to my data, but only to 1st order, i.e. using only the lowest non-zero frequency? Then, I should have a slower — and, we expect, smoother — fit. It looks like this:

The fit isn’t very good. But it isn’t horrible either. There’s genuine (and statistically significant!) correlation between the data values and the model values. It obviously doesn’t capture the variation well, but it does capture some important aspects of the overall quantitative behavior.
It also highlights a difference when we try to model our data using only sufficiently “smooth” functions. Namely, that our model no longer matches all the data perfectly. There are differences, which we can call residuals. In the case of our 1st-order Fourier fit, the differences are substantial.
We could try to capture more of the “signal” — or so we might call the true value of y as a function of x if we thought such a thing even existed — by using a higher order Fourier series. If we go to 2nd order, we get this model:

The match is better but not great, and it’s already wiggling around faster than we were hoping for. But it is getting closer.
What if we try the “use only slow functions” strategy with polynomials? In this case “slow” generally means low degree while “fast” means high degree. If we limit ourselves to a 2nd-degree (quadratic) polynomial, we get this model of the data:

Now we’re getting somewhere! The fit is outstanding, it’s plenty “smooth” enough to satisfy anybody, and it’s always going in the “up” direction.
There are still residuals, although they’re quite small and don’t show any apparent pattern. What we have done is to separate the data into two parts: the smooth part (in this case, a quadratic polynomial) and the rough part (the residuals).

We might even hypothesize that the smooth (in this case, the quadratic fit) is our best approximation of reality, and that the residuals are an example of the “noise” (departure from expectation) in the system.
And we’d be exactly right. These data were created by computing a quadratic function and adding random noise.
Noise Response
Since the signal itself is quadratic, so is the best polynomial degree for smoothing. For higher degree polynomials, the excess wiggling — especially at the endpoints — is due to the noise in the data. If we fit a straight line (a 1st-degree polynomial) to some data, then we’ve modelled the data with two functions (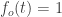



The first two orthogonal polynomials are just 


Two things are worth noting near the beginning and end of the observed time span. First, the values are larger, more so the larger the degree of the orthogonal polynomial. Second, the wiggles get closer together, i.e. they get faster. These properties of the fit functions persist in the final result, so when we use a high-degree polynomial we tend to get much larger uncertainty (i.e. noise response) as well as bigger and faster wiggles (also due to noise alone) near the beginning and end, exactly as we observed with our 8th-degree polynomial fit. A higher polynomial degree usually only makes things worse.
The probable error of a polynomial smooth which is due to noise alone is determined by something which we can call the “uncertainty function,” which gives the expected contribution of that polynomial to the variance of the estimated y value at a given x value. The uncertainty function tallies variance, but we can take its square root to compute the “standard error function” giving the probable error as a function of time. Here it is for polynomials of degree zero (a constant) up through degree 5, for polynomials which cover the time span 

Note how the uncertainty (i.e. the contribution of noise to the smooth function) is exaggerated near the endpoints, the more so the higher the polynomial degree — with just a 5th-degree polynomial, the standard errors are already three times as large at the endpoints as in the middle. And, don’t forget about that extra wiggling near the enpoints too; the combination of exaggerated endpoint uncertainty and exaggerated endpoint wiggling makes polynomial smoothing with degree higher than 3 or 4 at the most extremely untrustworthy near the endpoints of the time span.
Function Misfit
The “fast” (high-degree) polynomials had too much wiggling at the endpoints, but the slow (2nd-degree) worked fine. Of course that’s because the signal itself was a 2nd-degree polynomial. For Fourier series on the other hand, even in the “slow” case it didn’t fit very well. For the Fourier series the fit is poor because Fourier series are designed to create a periodic function. Whatever smooth function it returns will actually be periodic with period equal to the time span of the observed data. In fact we get the same smooth function if we fit a Fourier series to repeated copies of the data:

Note that in order to repeat, it has to dive back down at the end of each “cycle” toward those low values at the beginning of the next “cycle.” To do so, it has to exaggerate the wiggles, especially at the end. And that’s just to fit the signal, even without any noise. This is another case where the essential properties of the functions we’re using persist in the final result.
There are many ways to ameliorate this (and other) problems, but none of them entirely eliminate it. The fact remains that periodic functions have essential tendencies which persist in any Fourier-based smooth, and the problematic aspect is the behavior of the smooth near the endpoints.
It should be mentioned that for times well away from the endpoints, a polynomial smooth and a Fourier-based smooth both give oustanding results if the “time scale” (cutoff frequency for Fourier, polynomial degree for polynomials) is well chosen.
A More Generic Smooth
We’ve tried using classes of functions (polynomials, Fourier series) and restricting them to the “slow” ones in order to keep things sufficiently “smooth.” Perhaps instead we could seek some completely general smooth function which optimizes some criterion which combines both “fit” (how closely does it match the data) with “smoothness.” It’s easy to define how well it fits the data — the sum of the squares of the residuals is only the most common of many methods. But how do we define “smoothness” for some function in general?
The idea is that it’s the bending of the smooth curve that accounts for its “roughness,” and that the bending is measured by the second time derivative of the function. Of course, for that to exist the function has to be twice-differentiable, but that’s fine because we want a nice “smooth” function. It may not be “technically” smooth (infinitely differentiable) but it will at least be smooth-looking.
To measure of the goodness-of-fit (or should I say badness-of-fit), take the usual sum of the squared residuals. To measure the roughness, integrate the square of the 2nd derivative over the observed time span. Combine these two quantities into a weighted average, giving more weight to the roughness if you want an extra-smooth smooth but more weight to the badness-of-fit if you want an extra-good fit. Hence this method involves a parameter (actually it can involve many, but let’s not get into details) which controls how “smooth” the final smooth will be. This is nothing new, with polynomials we controlled smoothness by polynomial degree and with Fourier series by cutoff frequency.
Then: find the function which minimizes the weighted average of badness-of-fit and roughness. The solution turns out to be a function which is not smooth, i.e. not infinitely differentiable, but is piecewise-smooth, i.e. it’s made of a finite number of pieces which are themselves smooth. Furthermore, the pieces are joined as smoothly as possible by requiring that where they meet, they have the same value, the same derivative, and the same 2nd derivative. The result is called a spline smooth. The pieces themselves turn out to be cubic polynomials, so the smooth function is sometimes referred to as a “cubic spline.” If we apply this method to our toxicity data, with a reasonably smooth smooth we get this:

Global and Local Smooths
Fitting functions like polynomials or Fourier series to the entire set of data, and finding a function which optimizes some measure of total goodness as a spline smooth does, might be called “global” smoothing methods because they fit a smooth to the entire data set, both computationally and conceptually. However, one can also look at smoothing as a local problem, in which the value of the smooth at some particular time is determined by the data values which are nearby in time to the given moment. In the next post, we’ll take a look at some methods and issues related to local smoothing.



Ah! The lesson begins! Thank you!
Thanks for this. A couple of the functions haven’t been formatted correctly (e.g. $f_j(t) = t^j$), which initially threw me a bit!
[Response: Oops. Fixed.]
Very clear, even to a stats ignoramus. Looking forward to the next post.
Can you recommend a good technical reference?
“not infinitely differentiable”
Stupid question, but isn’t it possible to do this in a $C^\infy$ way. Just use a $C^\infty$ partition of unity on top of the cubic spline.
Say the cubics in the spline are $f_1, \dots f_r$ with closed interval domains $I_1, \dots I_r$. Extend the intervals very slightly and make them open. Then choose a $C^\infty$ partition of unity $\phi_1, \dots \phi_r$ subordinate to the $I_k$s. The sum of the products $\sum f_i \phi_i$ will be $C^\infty$ and should be very very very close to the cubic spline.
Why you would want a $C^\infty$ spline? I have no idea. (hence the “stupid”).
So you clearly cannot do an analytic spline, but I think you could do a $C^\infty$ one.
[Response: Perhaps you could — but it wouldn’t optimize the weighted average of badness-of-fit and roughness.]
That didn’t stop Roy Spencer from tying it on, entertainment excuse notwithstanding.
Great teaching
Excellent. Demonstrates convincingly how clueless the fake skeptics are that try to fit a 6th-degree polynomial to non-periodic data.
It seems utterly ridiculous for more than one reason, after reading this post. Tamino’s pretty cool.
Heh. After re-reading tamino’s post, and some of the comments… I now realise my comment above regarding periodicity is rather foolish, since it applies to Fourier series rather than polynomials. Ah, well, that’s how we learn. Looking forward to Smooth 2.
Thanks Tamino. Always interesting to learn more about statistics and their use, and misuse! And Happy New Year!
Really helpful post. Thank you so much for taking the time to put this together.
That was beatifully clear, yet concise. You really are very good at this explaining lark. Thanks for taking the time.
BTW if you wanted yet more things to do, this UK argument about stats as applied to wind-farm output degredation over time, could really use some of your expertise: http://www.carboncommentary.com/2013/12/31/3394/comment-page-1#comment-58206 (That post summarises and has links to the original report, David McKay’s rebuttal, and the REF response, as well as some simplistic analysis of its own). I’d like to know if the REF or McKay are right about the stats analysis being ‘identifiable’ or not. It seems very likley that the REF are wrong (they usually are), but it’d be good to know _why_.
Without fully reading, I do not see where necessary power plant outages for maintenance/refueling are factored in on the fossil/nuclear side.
Nuke: http://www.eia.gov/todayinenergy/detail.cfm
Oil: ???
The issue is that if you have a model function of the form:
f(x) = … + A*x + B*x + …
Where A and B are calibrated parameters, you can never find unique values of A and B to best-fit the observed data because you can always increase A by +1 and decrease B by -1 and get the same result. This is especially problematic if you are primarily interested in finding the “correct” value of A but not at all interested in the value of B. So, unless you severely restrict the value of B (and can show that this value is physically meaningful), you can’t really draw any conclusions about the “best fit” value of A that you derive from the observed data.
MacKay’s makes a really good case, in my opinion, that this has probably occurred in the REF report. The REF has a model that appears to include two terms that are both simple functions of time: one that the report discusses in depth (the rate at which turbine performance degrades with age) and one that it hardly discusses at all (loosely, the trend in UK windiness over the past couple of decades). Because it says so little about this second factor, it’s hard to tell if the rate of turbine efficiency decline derived by REF are meaningful.
Also, the counter-response from REF looks feeble to me. Hughes mainly argues that since his model is not quite as simple as the one MacKay analyzed, the above critique does not strictly apply, although he does admit at one point that it may well apply enough (see footnote on page 6 of http://www.ref.org.uk/attachments/article/303/B.gh.14.02.13.pdf).
At one point also admits that he can get age declines on the order of 2%/year with his model vs 5 to 6% in his original report. he tries to pass this off as “it’s still a decline” while ignoring the implications of the difference between a 2% and 5%/year decline over a 20 year time span, i.e.:
(1 – 0.02) ^ 20 = 0.67
vs.
(1 – 0.05) ^ 20 = 0.36
It seems pretty intuitively clear that if the declines with age were really as drastic as Hughes claimed, they’d have been unlikely to have escaped the practical attentions of wind farm operators over the span of a couple of decades…
But Why would you ever ask a wind farmer when you can just cowculate?
Wind-farm cowculations
Are really lots of fun
You put on hats
And bail on stats
Spread ordure by the ton
I’m not mathematician, but you say that Fourier series are a bad fit for non periodic datas (which is logical). However, I used Chebyshev polynomials for interpolation in the past and they were the best fit with the appropriate coefficients. Don’t those have a strong relation to Fourier cosine series ?
Chebyshev polynomials are not periodic, they are polynomials.
They are also orthogonal (wrt some weight function) so they they should do a good job of approximating (wrt to said weight function)
I just don’t see this strong relation wrt any Fourier series (other than the fact that you are projecting into the subspace generated by some orthogonal set of functions/vectors).
“Cycular Reasoning”
— by Horatio Algeranon
If you’ve got the nerve
You can fit a curve
With Fourier
You simply may
Assume it has a swerve
How to lie with statistics is easy, how not to lie with statistics is much much more difficult. I appreciate you sharing some of your knowledge. I saw the prior link you gave to the skeptic site who used a 6th order polynomial and tried to conclude from that fit. Yikes, it rankled with me right away… then I read this post and learned something. I love statistics, data visualization, and scientific computing so I like to think we are both cut from the same cloth. Thanks again for sharing. Thanks!!
Very nice, especially showing the higher order orthogonal polynomials. Here’s a slightly different way to look at this subject – fitting time series with noise. The two endpoints (and the points near them) have the least reliability, statistically speaking. That’s because you can only use neighbors on one side (e.g., the past for the right-hand end of the time axis) to compute an estimate of the fitted point. So you get less noise reduction and, if there is time-dependent behavior (e.g., trend) you don’t have that information from the future either. So fitting through those points will probably be biased, and certainly have larger variance, than for interior points. And if these values are the least reliable, well, the slopes are even less so.
If you try to fit with high order functions, you can see from their graphs in the article that they generally have the steepest slopes at the endpoints. So trying to fit them to these endpoints where the slope estimates are the least reliable is an exercise in misleading futility.
Really, the end points should carry less weight when calculating reasonable fits, for exactly these reasons. Most fitting procedures don’t do this, which is one more reason not to be too picky about fitted details near the endpoints.
On the topic of smoothness, I have found that using lowess but adaptively changing the width parameter based on penalizing too much wiggliness can arrive at very nice results. It takes more computation because you iterate extra times, but it can be worth it.
An important point which is often missed is that if there is some theoretical guidance as to the form of the function, you should use that function to do the fit.
Tangential: if anyone knows the Washington Post ‘Capitol Weather Gang’ bloggers, some education slap upside the head is needed there for stuff like:
“… the 30 years nominally (arbitrarily?) regarded as minimal
to warrant being considered climate.”
in http://www.washingtonpost.com/blogs/capital-weather-gang/wp/2013/12/24/arctic-warming-jet-stream-coupling-may-portend-another-winter-of-extreme-storms-and-cold-air-outbreaks/
Frank,
Your comparison of the 1940-1975 temperature with the present ‘hiatus’ appears to suggest that global surface temperature has been recently in a ‘hiatus’ for more years than it actually has. It is only since 2007 that GISS stopped accelerating upwards which sort of suggests that there was no ‘hiatus’ prior to that. (Note here (usually two clicks to ‘download yor attachment’) the red trace of the rising slope of a linear regression of the post-1980 GISS data prior to 2007.) If you then adjust for ENSO (as you appear to be happy to do) the ‘hiatus’ disappears entirely.
And that I think addresses all of your comment.
Hank-san: Refer them here:
http://bartonpaullevenson.com/30Years.html
Paul Clark thought the smooth curve of global surface temperature anomalies looked wrong because that curve is still going up over the last 10+ years at roughly the same rate as it has for the last 30 years. Everyone knows there has been a dramatic reduction in the rate of warming of GISS surface temperature (but not all measures of global temperature) over the last 10+ years. Should Paul really be criticized for recognizing that the smoothed curve doesn’t show this recent “hiatus” in warming (as some climate scientists call it) and for trying to find a smoothing method that shows this phenomena? In this post, you have demonstrated that a sixth degree polynomial wasn’t a good choice. However, the inability to see the reduced recent warming trend in the smooth curve arises because both Rahmstorf and you – rightly or wrongly – have chosen to smooth over a long period. Your choice allows the rapid warming trend from the 1990’s to be “smoothed into” the greatly reduced trend of the 2000’s. If the data had been smoothed over a shorter period, the curve would have flatter in the 2000’s. Why don’t you show Paul and other readers how the smoothing period changes the appearance of the smoothed curve and the interpretation that those with open minds might draw from it?
If you truncated the global temperature record in the late 1940s and used the same smoothing method, the smoothed curve probably would be rising at the end and not show any hint that temperature had been flat for the last decade. As we now know, that hiatus in warming lasted three decades. When we look at the 1940’s with un-truncated data, the smooth curve is flat in the 1940’s because smoothing incorporates data from the 1950’s (and 1960’s?), not just the warming 1930’s (and 1920s?). IMO, it doesn’t make sense to wait until at least 2020 to contemplate the possibility that temperatures leveled out in the 2000’s (as they did in the 1940s)..
ALL smoothing methods have the potential to distort data, particularly at the beginning and end – where up to half as many data points are being used in calculating the smoothing. What period should be used to smooth GISS temperature data? (Unfortunately, the Moore method used by Rahmstorf is behind a paywall, so I haven’t read it.) a) If one is interested in conveying information about climate, which usually implies a period of at least 30 years, then smoothing over an even longer period might be appropriate. b) If one is interested in retaining as much signal as possible, one should use the shortest period which removes most of the “obvious” high-frequency noise. When annual mean temperature is plotted, most of the high frequency noise is associated with ENSO. It should be possible to eliminate noise from ENSO while retaining the information that the warming trend was different in the 1990’s and 2000’s. In any case, distinguishing between signal and noise is difficult and potentially arbitrary. The warming around 1940 is sometimes attributed to unforced natural variation – low frequency noise that would be nearly impossible to remove by smoothing.
Frank,
You have apparently not read the previous post on the November GISS data. You refer to supposed flattening of the annual GISS record, but the data in question was the November data. A brief examination of the graphs in the previous post shows that your objection is simply not correct.
Having a shorter smoothing time so that you leave in much of the noise is certainly not the correct method of analyzing the data in any case. People with “open minds” who are open to suggestions that are not statistically valid because large amounts of noise were left in the data are not scientists.
Michael: You can use the climate plotter at Nick Stoke’s (a non-skeptic) web site (http://moyhu.blogspot.com) and vary the smoothing period for GISS data. Try a 10-year binomial smooth. The flattening in the 2000’s is clearly apparent, even though the last visible datapoint is only for 2006. The data has been smoothed enough so that the 1998 El Nino is barely perceptible. Unlike the graphs seen in this post, Nick’s plotter does NOT smooth the data all the way through 2013 (when almost half the data needed calculate a simple smooth curve lie in the future), so a 15-year smooth with the last datapoint in 2003 doesn’t show a plateau. If Tamino showed a 15-year (rather than 30-year) smooth, the flattening Paul Clark was expecting would be apparent by 2010.
The 1982 and 1993 volcanos are apparent even with a 20-year binomial smooth and the 1930’s-1940’s warming (unforced natural variability) is visible with an 80-year smooth. Smoothing doesn’t magically remove all “noise”, just high-frequency variability – whether it is unforced, naturally-forced, or anthropogenically-forced.
[Response: You really don’t get it. Sad. Perhaps after the next post you will — but I doubt it.]
However dramatic you want to call it, it is not a statistically significant slowdown. That means the “slowdown” is indistinguishable from noise.
Chris: What do you mean by “statistically significant”? For the period 1975-1995, I calculate a linear warming rate of +0.159 degC/decade, with a 95% confidence interval of +0.095 to +0.224 degC/decade. For the period 2000-2013, I get a linear warming rate of +0.048 degC/decade, with a 95% confidence interval of -0.039 to +0.134 degC. The central estimates for each period lies outside the 95% confidence interval for the other, so I would call the difference in trend statistically significant. I used 21 and 13 mean annual temperatures in this calculation to avoid having to deal with the auto-correlation in monthly temperature anomalies. (The residuals don’t show obvious auto-correlation, but there may be a little left.)
The results of analyses of this type will vary with starting and stopping dates, providing plenty of opportunities for charges of cherry-picking. For the record, I picked dates that were multiples of five, avoided the 1998 El Nino, and included 2013 (slightly above the trend line) despite missing December. If I started in 2001 or 1998, the recent trend would be smaller; if I started in 1999, the recent trend would be +0.07 degC/decade. If you can point me to a better analysis which reaches the opposite conclusion, please provide a link so I can see what I did wrong.
(Doug Keenan has debated with the British Met Office about whether it is appropriate to assess the statistical significance of global warming using a linear statistical models. If you agree with him, my analysis would be inappropriate.)
A number of papers have appeared recently trying to explain the recent “hiatus” in warming. Trenberth thinks the missing heat has gone into the deep ocean, Xue thinks the hiatus was produced by natural variability in Eastern Equatorial Pacific (the decline in strong El Nino’s), and another paper thinks the missing warming is in the Arctic far from stations. You can find many links to this subject at Skeptical Science by searching for “hiatus”. When so much attention is now being paid to the hiatus, it is unrealistic to arbitrarily dismiss it as “noise” or “statistically insignificant” – even though its duration is too short to be termed “climate” or “climate change”.
[Response: Frank, you’re on the wrong blog. We’ve heard this bullshit before and we see right through you. Better than you do yourself.]
Frank,
If you are addressing each of you critics in turn, do note there is one I managed to position above rather than below (- a touch of the ‘fat thumb’ affliction I suffer from).
Regarding your analysis of the years 2000-13.
Do you not feel you could have overlooked some vital consideration within your analysis? I repeated your analysis, keeping to decades to avoid accusations of cherry picking (heaven forefend) and for 2010-2013 I get proof of an increase in the rate of warming +0.21ºC/decade with 95% confidence interval 0.14ºC – 0.28ºC. My central figure lies outside your 95% and vica versa so by your method this is ‘statistically significant’ against your 2000-13 result.
Now, I don’t think this result signals the end of the ‘hiatus’ in global surface temperature so where have I gone wrong? Or, given this is your method of analysis, where have you gone wrong?
“Fits n Twits”
— by Horatio Algeranon
Fitting a curve
To interpolate
You might observe
Is well and great
But using fits
To extrapolate
Takes some twits
Who mathturbate
A rather good example of the Fourier method of mis-analysis being employed by denialists appeared recently in a paper from Germany Ludecke et al 2013 – Multi-periodic climate dynamics: spectral analysis of long-term instrumental and proxy temperature records, a carbon copy of the second-last graphic in the post above. Two of the jokers actually provide comment on their paper to predict a return to 1870s temperatures by 2100 (actually 1880s by 2130s it being a 254-year cycle). Mind, they do fail to mention the return to 1780s temperatures by 2030. I’m sure the graph in the published paper would have shown it but for them running out of ink!
They fail to include CET or BEST records (or a note from their mums) which would show this for the nonsense it really is.
The only evidence they provide for predicting temperatures repeat every 254 years is (bar ‘scafettatating’ their sunspots) a long chat with a stalagmite in some deep dark cave, although they provide no transcript of the conversation only some resulting analyses.
Worse, they used a bad set of data with a known problems
Re Bad Data Sets
I was familiar with CET having early measurements taken in out-buildings. That the problem was more widespread had never occurred to me.
One point in Ludecke et al that I was surprised they got away with was their comment that the coming coldness would be due to their 64-year cycle, “essentially” was the word I remember. I noticed that all their cycles were “essentially” beat frequencies of 254 years and I was curious enough to check how they synchronised with their 2005ish peak. All bar one peaked together or trailed by 3 or 6 years. So the cooling due to a 64-year cycle – the wheels have fallen of that one. Ludecke et al will be needing a new pedal car to play with.
Tamino,
As there is no current open thread, I hope you will excuse my posting this question here. Have you considered the possibility of using order statistics to demonstrate that extreme events are on the rise? It seems as if it could yield some interesting results.
Frank:
Your method of calculating these confidence intervals is completely up the creek. If you took your own advice and referred to skeptical science then you could use the calculator implemented there: http://www.skepticalscience.com/trend.php Using that calculator yields (with GISTEMP) trends of 0.149±0.106 deg C/decade (±2σ) for 1975-1995 and 0.062±0.153 deg C/decade for 2000 to the present.